
Automatyczne rozpoznawanie mowy (ASR) przeszło długą drogę. Chociaż został wynaleziony dawno temu, prawie nigdy nie był używany przez nikogo. Jednak czas i technologia znacznie się zmieniły. Transkrypcja audio znacznie się rozwinęła.
Technologie takie jak sztuczna inteligencja (sztuczna inteligencja) napędzają proces tłumaczenia audio na tekst, zapewniając szybkie i dokładne wyniki. W rezultacie zwiększyły się również jego aplikacje w świecie rzeczywistym, a niektóre popularne aplikacje, takie jak Tik Tok, Spotify i Zoom, osadzają ten proces w swoich aplikacjach mobilnych.
Zbadajmy więc ASR i odkryjmy, dlaczego jest to jedna z najpopularniejszych technologii w 2022 roku.
Czym jest mowa na tekst?
Mowa na tekst to technologia wspomagana sztuczną inteligencją, która tłumaczy ludzką mowę z postaci analogowej na cyfrową. Ponadto cyfrowa postać zebranych danych jest transkrypcja do formatu tekstowego.
Mowa na tekst jest często mylona z rozpoznawaniem głosu, które jest całkowicie odmienne od tej metody. W rozpoznawaniu głosu nacisk kładziony jest na identyfikację wzorców głosowych ludzi, podczas gdy w tej metodzie system próbuje zidentyfikować wypowiadane słowa.
Popularne nazwy mowy na tekst
Ta zaawansowana technologia rozpoznawania mowy jest również popularna i określana nazwami:
- Automatyczne rozpoznawanie mowy (ASR)
- Rozpoznawanie mowy
- Komputerowe rozpoznawanie mowy
- Transkrypcja audio
- Czytanie ekranu
Zrozumienie działania automatycznego rozpoznawania mowy
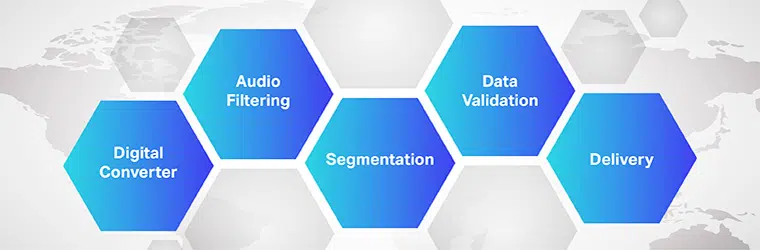
Działanie oprogramowania do tłumaczenia audio na tekst jest złożone i wymaga wykonania wielu kroków. Jak wiemy, zamiana mowy na tekst to ekskluzywne oprogramowanie przeznaczone do konwersji plików audio do edytowalnego formatu tekstowego; robi to, wykorzystując rozpoznawanie głosu.
Przetwarzanie
- Początkowo, za pomocą przetwornika analogowo-cyfrowego, program komputerowy stosuje algorytmy językowe do dostarczonych danych, aby odróżnić wibracje od sygnałów dźwiękowych.
- Następnie odpowiednie dźwięki są filtrowane poprzez pomiar fal dźwiękowych.
- Co więcej, dźwięki są rozdzielane/segmentowane na setne lub tysięczne sekundy i dopasowywane do fonemów (mierzalna jednostka dźwięku do odróżnienia jednego słowa od drugiego).
- Fonemy są następnie analizowane przez model matematyczny w celu porównania istniejących danych ze znanymi słowami, zdaniami i frazami.
- Wyjście jest w postaci pliku tekstowego lub komputerowego pliku audio.
[Przeczytaj także: Kompleksowy przegląd automatycznego rozpoznawania mowy]

Jakie są zastosowania zamiany mowy na tekst?
Istnieje wiele zastosowań oprogramowania do automatycznego rozpoznawania mowy, takich jak
- Wyszukiwanie treści: Większość z nas przeszła od pisania liter na naszych telefonach do naciskania przycisku, aby oprogramowanie rozpoznało nasz głos i zapewniło pożądane rezultaty.
- Obsługa klienta: Czatboty i asystenci AI, którzy mogą prowadzić klientów przez kilka początkowych etapów procesu, stały się powszechne.
- Napisy kodowane w czasie rzeczywistym: Wraz ze zwiększonym globalnym dostępem do treści, napisy kodowane w czasie rzeczywistym stały się znaczącym i znaczącym rynkiem, popychając ASR do przodu w zakresie ich wykorzystania.
- Dokumentacja elektroniczna: Kilka działów administracji zaczęło używać ASR do realizacji celów dokumentacyjnych, zapewniając większą szybkość i wydajność.
Jakie są kluczowe wyzwania dla rozpoznawania mowy?
Adnotacja dźwiękowa nie osiągnął jeszcze szczytu swojego rozwoju. Nadal istnieje wiele wyzwań, którym inżynierowie starają się przeciwdziałać, aby system był wydajny, takich jak:
- Uzyskanie kontroli nad akcentami i dialektami.
- Rozumienie kontekstu wypowiadanych zdań.
- Oddzielenie szumów tła w celu wzmocnienia jakości wejściowej.
- Przełączanie kodu na różne języki w celu wydajnego przetwarzania.
- Analiza wizualnych wskazówek wykorzystywanych w mowie w przypadku plików wideo.
Transkrypcje audio i rozwój sztucznej inteligencji mowy na tekst
Największym wyzwaniem związanym z oprogramowaniem do automatycznego rozpoznawania mowy jest tworzenie wyników w 100% dokładnie. Ponieważ surowe dane są dynamiczne i nie można zastosować pojedynczego algorytmu, dane są opisywane w celu wytrenowania sztucznej inteligencji, aby zrozumiała je we właściwym kontekście.
Aby przeprowadzić ten proces, należy zrealizować określone zadania, takie jak:
 Rozpoznawanie nazwanych jednostek (NER): NER to proces identyfikacji i segmentacji różnych nazwanych podmiotów na określone kategorie.
Rozpoznawanie nazwanych jednostek (NER): NER to proces identyfikacji i segmentacji różnych nazwanych podmiotów na określone kategorie.- Analiza nastrojów i tematów: Oprogramowanie wykorzystujące wiele algorytmów przeprowadza analizę sentymentu dostarczonych danych, aby zapewnić bezbłędne wyniki.
 Rozpoznawanie nazwanych jednostek (NER):
Rozpoznawanie nazwanych jednostek (NER): - Analiza zamiarów i konwersacji: Wykrywanie intencji ma na celu wytrenowanie sztucznej inteligencji w rozpoznawaniu intencji mówiącego. Służy głównie do tworzenia chatbotów opartych na sztucznej inteligencji.
Wnioski
Technologia zamiany mowy na tekst jest obecnie na bardzo zaawansowanym etapie. Ponieważ coraz więcej urządzeń cyfrowych zawiera w swoich aplikacjach asystentów wyszukiwania głosowego i sterowania, zapotrzebowanie na transkrypcję audio ma wzrosnąć. Jeśli chcesz dodać tę imponującą funkcję do swojej aplikacji, skontaktuj się z ekspertami firmy Shaip w zakresie zbierania danych mowy, aby poznać wszystkie szczegóły.


