
Klucz do pokonania przeszkód w rozwoju sztucznej inteligencji: bardziej wiarygodne dane
Dzisiaj przeciętny człowiek ma w kieszeni miliony razy więcej mocy obliczeniowej niż NASA musiała wylądować na Księżycu w 1969 roku. To samo wszechobecne urządzenie, które dogodnie demonstruje obfitość mocy obliczeniowej, spełnia również inny warunek złotego wieku AI: obfitość danych. Według spostrzeżeń Information Overload Research Group 90% danych na świecie powstało w ciągu ostatnich dwóch lat. Teraz, gdy wykładniczy wzrost mocy obliczeniowej w końcu zbiegł się z równie błyskawicznym wzrostem generowania danych, innowacje w zakresie danych AI eksplodują tak bardzo, że niektórzy eksperci sądzą, że zapoczątkują czwartą rewolucję przemysłową.
Dane National Venture Capital Association wskazują, że sektor AI odnotował rekordowe inwestycje w wysokości 6.9 miliarda dolarów w pierwszym kwartale 2020 roku. Nietrudno dostrzec potencjał narzędzi AI, ponieważ jest on już wykorzystywany wokół nas. Niektóre z bardziej widocznych przypadków użycia produktów AI to silniki rekomendacji naszych ulubionych aplikacji, takich jak Spotify i Netflix. Chociaż fajnie jest odkryć nowego artystę do posłuchania lub nowy program telewizyjny do obejrzenia, te wdrożenia są raczej niską stawką. Inne algorytmy oceniają wyniki testów — częściowo określające, gdzie studenci są przyjmowani na studia — a jeszcze inne przesiewają życiorysy kandydatów, decydując, którzy kandydaci dostaną konkretną pracę. Niektóre narzędzia sztucznej inteligencji mogą mieć nawet konsekwencje dla życia lub śmierci, takie jak model sztucznej inteligencji, który bada raka piersi (który przewyższa lekarzy).
Pomimo stałego wzrostu zarówno w rzeczywistych przykładach rozwoju sztucznej inteligencji, jak i liczby start-upów rywalizujących o stworzenie nowej generacji narzędzi transformacyjnych, wyzwania związane z efektywnym rozwojem i wdrażaniem wciąż pozostają. . W szczególności dane wyjściowe AI są tak dokładne, jak pozwalają na to dane wejściowe, co oznacza, że jakość jest najważniejsza.

Poruszanie się po złożonych wymaganiach dotyczących zgodności
Jakby znalezienie danych wysokiej jakości nie było wystarczająco trudne, niektóre branże, które mogą najwięcej zyskać na innowacjach dotyczących danych AI, są również najbardziej uregulowane. Opieka zdrowotna jest prawdopodobnie najlepszym przykładem i chociaż ankieta przeprowadzona przez HIT Infrastructure wykazała, że 91% osób z branży uważa, że technologia może poprawić dostęp do opieki, optymizm jest łagodzony przez fakt, że 75% postrzega ją jako zagrożenie dla bezpieczeństwa i prywatności pacjentów — a nie tylko pacjenci są zagrożeni.
Ogólne przepisy uchwalone w ustawie o przenośności i odpowiedzialności w ubezpieczeniach zdrowotnych przecinają się obecnie z różnymi lokalnymi przeszkodami w zakresie zgodności danych, takimi jak europejskie ogólne rozporządzenie o ochronie danych, kalifornijska ustawa o ochronie prywatności konsumentów w Stanach Zjednoczonych i ustawa o ochronie danych osobowych w Singapurze. Do tych lokalnych przepisów dołączy wiele innych, a ponieważ telezdrowie staje się bardziej znaczącym źródłem danych dotyczących opieki zdrowotnej, prawdopodobne jest, że przepisy jeszcze mocniej uchwycą dane pacjentów w trakcie przesyłu. Na . W rezultacie bezpieczna i zgodna platforma chmurowa Shaip okaże się jeszcze bardziej wartościowym sposobem gromadzenia i uzyskiwania dostępu do danych medycznych w celu szkolenia produktów AI.
Informacje umożliwiające identyfikację osoby mogą stanowić poważne zagrożenie dla rozwoju sztucznej inteligencji, ale nawet całkowicie zgodna implementacja jest zagrożona, jeśli nie może dostarczyć dokładnych wyników, które pochodzą tylko z różnych danych treningowych. Badanie opublikowane w 2020 r. w Journal of the American Medical Association wykazało, że algorytmy uczenia maszynowego w medycynie są najczęściej szkolone na podstawie danych od pacjentów z Kalifornii, Nowego Jorku i Massachusetts. Biorąc pod uwagę, że ci pacjenci stanowią mniej niż jedną piątą populacji Stanów Zjednoczonych, nie mówiąc już o reszcie świata, trudno sobie wyobrazić, jak te modele mogłyby dawać wyniki poza stronniczymi.

 Zdając sobie sprawę z trudności w zabezpieczeniu zgodnych, zróżnicowanych geograficznie informacji, Shaip oferuje licencjonowane dane dotyczące opieki zdrowotnej z wielu różnych regionów, specjalnie wyselekcjonowane w celu skonstruowania dokładnych algorytmów. Dane te mają postać tekstu, takiego jak dokumentacja medyczna lub informacje o roszczeniach, medyczne obrazowanie diagnostyczne, takie jak tomografia komputerowa, dźwięk, taki jak notatki mówione od lekarzy lub rozmowy między lekarzami a pacjentami, a nawet wideo z wyników MRI. Jest również całkowicie zdeidentyfikowany i zanonimizowany, chroniąc Twoją organizację zarówno przed etycznymi, jak i finansowymi konsekwencjami, które mogą wynikać z naruszenia którejkolwiek z rosnącej liczby przepisów regulujących dane o pochodzeniu zarówno krajowym, jak i międzynarodowym.
Zdając sobie sprawę z trudności w zabezpieczeniu zgodnych, zróżnicowanych geograficznie informacji, Shaip oferuje licencjonowane dane dotyczące opieki zdrowotnej z wielu różnych regionów, specjalnie wyselekcjonowane w celu skonstruowania dokładnych algorytmów. Dane te mają postać tekstu, takiego jak dokumentacja medyczna lub informacje o roszczeniach, medyczne obrazowanie diagnostyczne, takie jak tomografia komputerowa, dźwięk, taki jak notatki mówione od lekarzy lub rozmowy między lekarzami a pacjentami, a nawet wideo z wyników MRI. Jest również całkowicie zdeidentyfikowany i zanonimizowany, chroniąc Twoją organizację zarówno przed etycznymi, jak i finansowymi konsekwencjami, które mogą wynikać z naruszenia którejkolwiek z rosnącej liczby przepisów regulujących dane o pochodzeniu zarówno krajowym, jak i międzynarodowym.
Pokonywanie przeszkód w rozwoju AI
Wysiłki w zakresie rozwoju sztucznej inteligencji obejmują znaczne przeszkody bez względu na branżę, w której działają, a proces przejścia od wykonalnego pomysłu do udanego produktu jest najeżony trudnościami. Pomiędzy wyzwaniami związanymi z pozyskaniem właściwych danych a potrzebą ich anonimizacji w celu zapewnienia zgodności ze wszystkimi odpowiednimi przepisami, można odnieść wrażenie, że faktycznie skonstruowanie i przeszkolenie algorytmu jest łatwą częścią.
Aby zapewnić swojej organizacji wszelkie korzyści niezbędne do zaprojektowania przełomowego rozwoju sztucznej inteligencji, warto rozważyć współpracę z firmą taką jak Shaip. Chetan Parikh i Vatsal Ghiya założyli firmę Shaip, aby pomagać firmom w opracowywaniu rozwiązań, które mogą przekształcić opiekę zdrowotną w Stanach Zjednoczonych. Po ponad 16 latach działalności nasza firma rozrosła się do ponad 600 członków zespołu i współpracowaliśmy z setkami klientów, aby przekuć ciekawe pomysły w rozwiązania AI.
Dzięki naszym pracownikom, procesom i platformie działającej dla Twojej organizacji, możesz natychmiast odblokować następujące cztery korzyści i katapultować swój projekt do pomyślnego zakończenia:
1. Zdolność do wyzwolenia analityków danych
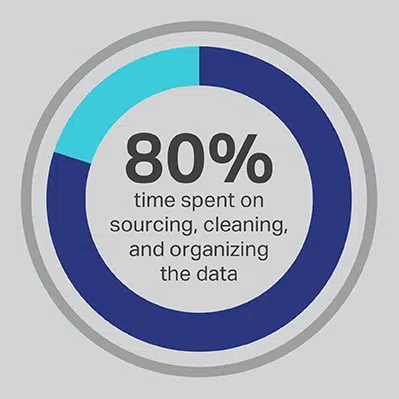
Nie ma wątpliwości, że proces rozwoju sztucznej inteligencji wymaga znacznej inwestycji czasu, ale zawsze możesz zoptymalizować funkcje, na których wykonywanie Twój zespół spędza najwięcej czasu. Zatrudniłeś swoich naukowców zajmujących się danymi, ponieważ są oni ekspertami w opracowywaniu zaawansowanych algorytmów i modeli uczenia maszynowego, ale badania konsekwentnie pokazują, że ci pracownicy faktycznie spędzają 80% swojego czasu na poszukiwaniu, czyszczeniu i porządkowaniu danych, które będą napędzać projekt. Ponad trzy czwarte (76%) naukowców zajmujących się danymi twierdzi, że te przyziemne procesy gromadzenia danych są również ich najmniej ulubioną częścią pracy, ale potrzeba wysokiej jakości danych pozostawia tylko 20% ich czasu na faktyczny rozwój, co jest najciekawsza i stymulująca intelektualnie praca dla wielu naukowców zajmujących się danymi. Pozyskując dane za pośrednictwem zewnętrznego dostawcy, takiego jak Shaip, firma może pozwolić swoim drogim i utalentowanym inżynierom danych na outsourcing ich pracy jako dozorców danych i zamiast tego spędzać czas na tych częściach rozwiązań AI, w których mogą one wytworzyć największą wartość.
2. Zdolność do osiągania lepszych wyników outcome
 Wielu liderów rozwoju sztucznej inteligencji decyduje się na wykorzystanie danych open source lub crowdsourcingowych, aby zmniejszyć wydatki, ale ta decyzja prawie zawsze kończy się kosztami wyższymi w dłuższej perspektywie. Tego typu dane są łatwo dostępne, ale nie mogą dorównać jakością starannie dobranym zestawom danych. Zwłaszcza dane pochodzące z crowdsourcingu są pełne błędów, pominięć i nieścisłości i chociaż te problemy można czasem rozwiązać w trakcie procesu rozwoju pod czujnym okiem inżynierów, wymagają one dodatkowych iteracji, które nie byłyby konieczne, gdybyś zaczynał od wyższych -jakość danych od początku.
Wielu liderów rozwoju sztucznej inteligencji decyduje się na wykorzystanie danych open source lub crowdsourcingowych, aby zmniejszyć wydatki, ale ta decyzja prawie zawsze kończy się kosztami wyższymi w dłuższej perspektywie. Tego typu dane są łatwo dostępne, ale nie mogą dorównać jakością starannie dobranym zestawom danych. Zwłaszcza dane pochodzące z crowdsourcingu są pełne błędów, pominięć i nieścisłości i chociaż te problemy można czasem rozwiązać w trakcie procesu rozwoju pod czujnym okiem inżynierów, wymagają one dodatkowych iteracji, które nie byłyby konieczne, gdybyś zaczynał od wyższych -jakość danych od początku.
Poleganie na danych o otwartym kodzie źródłowym to kolejny popularny skrót, który wiąże się z własnym zestawem pułapek. Brak zróżnicowania jest jednym z największych problemów, ponieważ algorytm wytrenowany przy użyciu danych open source jest łatwiej replikowany niż ten zbudowany na licencjonowanych zestawach danych. Idąc tą drogą, zapraszasz konkurencję ze strony innych uczestników rynku, którzy w każdej chwili mogą obniżyć Twoje ceny i zdobyć udział w rynku. Kiedy polegasz na firmie Shaip, uzyskujesz dostęp do najwyższej jakości danych zebranych przez wprawnych, zarządzanych pracowników, a my możemy udzielić Ci wyłącznej licencji na niestandardowy zestaw danych, który uniemożliwi konkurentom łatwe odtworzenie Twojej ciężko wywalczonej własności intelektualnej.
3. Dostęp do doświadczonych profesjonalistów
 Nawet jeśli Twój wewnętrzny skład obejmuje wykwalifikowanych inżynierów i utalentowanych naukowców zajmujących się danymi, Twoje narzędzia AI mogą korzystać z mądrości, która pochodzi tylko z doświadczenia. Nasi eksperci merytoryczni przewodzili licznym wdrożeniom sztucznej inteligencji w swoich dziedzinach i nauczyli się po drodze cennych lekcji, a ich jedynym celem jest pomoc w osiągnięciu Twoich. .
Nawet jeśli Twój wewnętrzny skład obejmuje wykwalifikowanych inżynierów i utalentowanych naukowców zajmujących się danymi, Twoje narzędzia AI mogą korzystać z mądrości, która pochodzi tylko z doświadczenia. Nasi eksperci merytoryczni przewodzili licznym wdrożeniom sztucznej inteligencji w swoich dziedzinach i nauczyli się po drodze cennych lekcji, a ich jedynym celem jest pomoc w osiągnięciu Twoich. .
Dzięki ekspertom dziedzinowym, którzy identyfikują, organizują, kategoryzują i oznaczają dane dla Ciebie, wiesz, że informacje wykorzystywane do trenowania Twojego algorytmu mogą przynieść najlepsze możliwe wyniki. Przeprowadzamy również regularne kontrole jakości, aby upewnić się, że dane spełniają najwyższe standardy i będą działać zgodnie z przeznaczeniem nie tylko w laboratorium, ale także w rzeczywistych sytuacjach.
4. Przyspieszona oś czasu rozwoju
Rozwój sztucznej inteligencji nie następuje z dnia na dzień, ale może to nastąpić szybciej, gdy współpracujesz z Shaipem. Własne gromadzenie danych i adnotacje tworzą istotne wąskie gardło operacyjne, które wstrzymuje resztę procesu rozwoju. Współpraca z Shaip zapewnia natychmiastowy dostęp do naszej ogromnej biblioteki gotowych do użycia danych, a nasi eksperci będą w stanie pozyskać wszelkie dodatkowe informacje, których potrzebujesz, dzięki naszej głębokiej wiedzy branżowej i globalnej sieci. Bez obciążenia związanego z sourcingiem i adnotacjami Twój zespół może od razu przystąpić do rzeczywistego rozwoju, a nasz model szkoleniowy może pomóc w identyfikacji wczesnych niedokładności w celu zmniejszenia liczby iteracji niezbędnych do osiągnięcia celów dotyczących dokładności.
Jeśli nie jesteś gotowy, aby zlecić na zewnątrz wszystkie aspekty zarządzania danymi, Shaip oferuje również platformę opartą na chmurze, która pomaga zespołom w bardziej wydajnym tworzeniu, zmienianiu i komentowaniu różnych typów danych, w tym obsłudze obrazów, wideo, tekstu i dźwięku . ShaipCloud zawiera szereg intuicyjnych narzędzi do walidacji i przepływu pracy, takich jak opatentowane rozwiązanie do śledzenia i monitorowania obciążeń, narzędzie do transkrypcji do transkrypcji złożonych i trudnych nagrań audio oraz komponent kontroli jakości zapewniający bezkompromisową jakość. A co najważniejsze, jest skalowalny, więc może się rozwijać wraz ze wzrostem różnych wymagań projektu.
Era innowacji AI dopiero się zaczyna, a w nadchodzących latach zobaczymy niesamowite postępy i innowacje, które mają potencjał, aby przekształcić całe branże, a nawet zmienić społeczeństwo jako całość. . W Shaip chcemy wykorzystać naszą wiedzę specjalistyczną, aby służyć jako siła transformacyjna, pomagając najbardziej rewolucyjnym firmom na świecie wykorzystać moc rozwiązań AI do osiągnięcia ambitnych celów.
Mamy duże doświadczenie w zastosowaniach opieki zdrowotnej i konwersacyjnej sztucznej inteligencji, ale posiadamy również umiejętności niezbędne do trenowania modeli dla niemal każdego rodzaju aplikacji. Aby uzyskać więcej informacji o tym, jak Shaip może pomóc w przeprowadzeniu Twojego projektu od pomysłu do realizacji, przejrzyj wiele zasobów dostępnych na naszej stronie internetowej lub skontaktuj się z nami już dziś.
