

Inteligentne modele sztucznej inteligencji muszą być intensywnie przeszkolone, aby móc identyfikować wzorce, obiekty i ostatecznie podejmować wiarygodne decyzje. Jednak wytrenowane dane nie mogą być wprowadzane losowo i muszą być oznaczone etykietami, aby pomóc modelom zrozumieć, przetworzyć i kompleksowo uczyć się na podstawie wyselekcjonowanych wzorców wejściowych.
W tym miejscu pojawia się etykietowanie danych, jako czynność oznaczania informacji lub raczej metadanych, zgodnie z konkretnym zbiorem danych, aby skupić się na zwiększeniu zrozumienia maszyn. Mówiąc prościej, etykietowanie danych selektywnie kategoryzuje dane, obrazy, tekst, dźwięk, wideo i wzorce w celu ulepszenia implementacji sztucznej inteligencji.
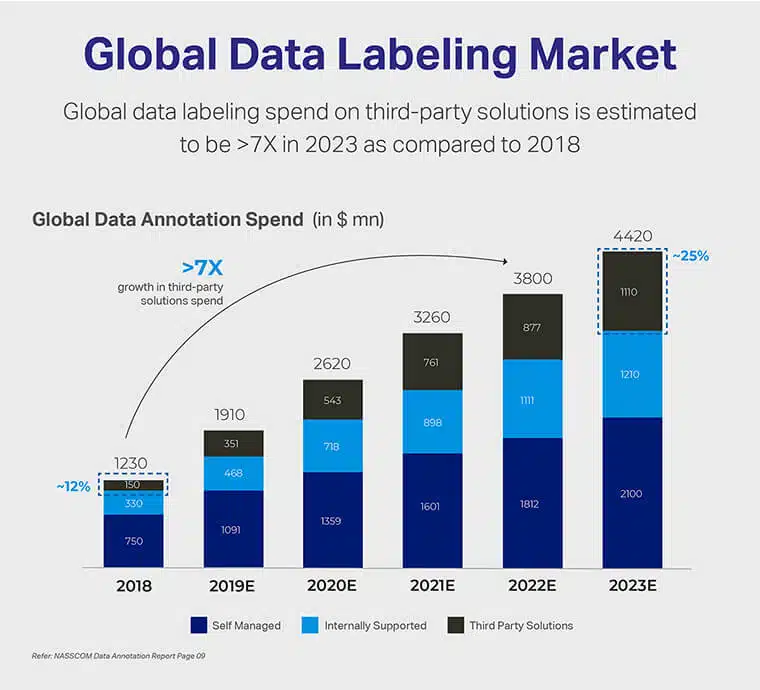
Zgodnie z NASSCOM Etykietowanie danych Raport, oczekuje się, że globalny rynek etykietowania danych wzrośnie o 700% do końca 2023 r. w porównaniu z 2018 r. Ten rzekomy wzrost najprawdopodobniej będzie uwzględniał przydział środków finansowych na samodzielnie zarządzane narzędzia do etykietowania, wspierane wewnętrznie zasobów, a nawet rozwiązań firm trzecich.
Oprócz tych ustaleń można również wywnioskować, że globalny rynek etykietowania danych zgromadził w 1.2 r. wartość 2018 mld USD. Spodziewamy się jednak, że będzie się ona skalować, ponieważ zakłada się, że wielkość rynku etykietowania danych osiągnie ogromną wycenę wynoszącą 4.4 mld USD. do 2023 roku.
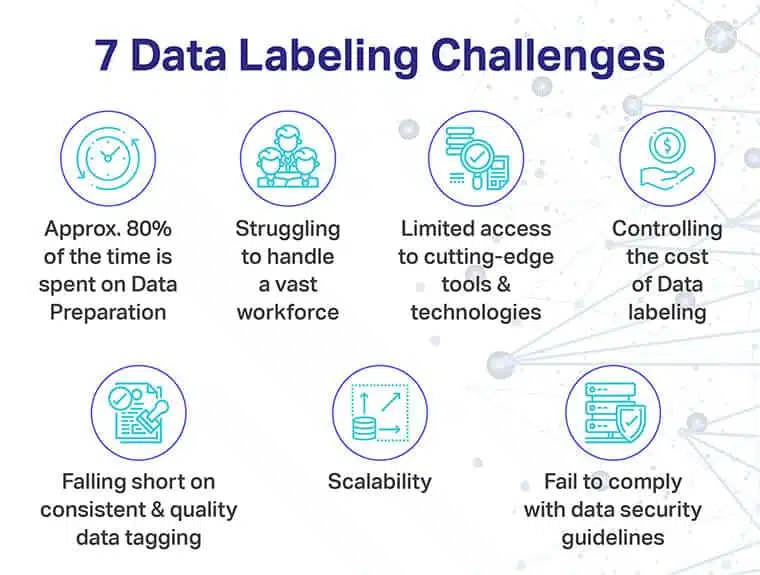
Etykietowanie danych jest potrzebą chwili, ale wiąże się z kilkoma wyzwaniami związanymi z wdrożeniem i ceną.
Niektóre z bardziej palących to:
- Powolne przygotowywanie danych dzięki zbędnym narzędziom czyszczącym
- Brak wymaganego sprzętu do obsługi ogromnej siły roboczej i nadmierna ilość zeskrobanych danych
- Ograniczony dostęp do awangardowych narzędzi do etykietowania i technologii wspierających
- Wyższy koszt etykietowania danych
- Brak spójności w przypadku jakościowego znakowania danych
- Brak skalowalności, czy i kiedy model AI musi objąć dodatkową grupę uczestników?
- Brak zgodności, jeśli chodzi o utrzymanie stabilnej postawy bezpieczeństwa danych podczas pozyskiwania danych i korzystania z nich

Chociaż można koncepcyjnie segregować etykietowanie danych, odpowiednie narzędzia wymagają sklasyfikowania pojęć zgodnie z charakterem zestawów danych. Obejmują one:
- Klasyfikacja audio: Zawiera kolekcję audio, segmentację i transkrypcję
- Etykietowanie obrazu: Obejmuje gromadzenie, klasyfikację, segmentację i oznaczanie kluczowych danych punktowych
- Etykiety tekstowe: Obejmuje wyodrębnianie i klasyfikację tekstu
- Etykietowanie wideo: Obejmuje takie elementy, jak kolekcja wideo, klasyfikacja i segmentacja
- Etykietowanie 3D: Funkcje śledzenia i segmentacji obiektów
Oprócz wspomnianej segregacji, zwłaszcza w szerszej perspektywie, etykietowanie danych dzieli się na cztery typy, w tym opisowe, oceniające, informacyjne i kombinacyjne. Klasyfikacja, ekstrakcja, śledzenie obiektów, które omówiliśmy już dla poszczególnych zestawów danych.

Etykietowanie danych to szczegółowy proces, który obejmuje następujące kroki, aby kategorycznie trenować modele AI:
- Zbieranie zbiorów danych za pomocą strategii, tj. wewnętrznych, open source, dostawców
- Etykietowanie zestawów danych zgodnie z Computer Vision, Deep Learning i funkcjami specyficznymi dla NLP
- Testowanie i ocena wyprodukowanych modeli w celu określenia inteligencji w ramach wdrożenia
- Zadowalająca akceptowalna jakość modelu i ostatecznie dopuszczenie go do wszechstronnego użytku

Właściwy zestaw narzędzi do oznaczania danych, synonim wiarygodnej platformy oznaczania danych, należy wybrać, mając na uwadze następujące czynniki:
- Rodzaj inteligencji, jaki chcesz, aby model posiadał za pomocą zdefiniowanych przypadków użycia
- Jakość i doświadczenie adnotatorów danych, aby mogli precyzyjnie korzystać z narzędzi
- Standardy jakości, o których myślisz
- Potrzeby dotyczące zgodności
- Narzędzia komercyjne, open-source i darmowe
- Budżet, który możesz oszczędzić
Oprócz wspomnianych czynników, lepiej zanotuj następujące kwestie:
- Dokładność etykietowania narzędzi
- Zapewnienie jakości gwarantują narzędzia
- Możliwości integracji
- Bezpieczeństwo i uodpornienie na wycieki
- Konfiguracja w chmurze, czy nie
- Sprawność zarządzania kontrolą jakości
- Fail-Safes, Stop-Gaps i skalowalna sprawność narzędzia
- Firma oferująca narzędzia
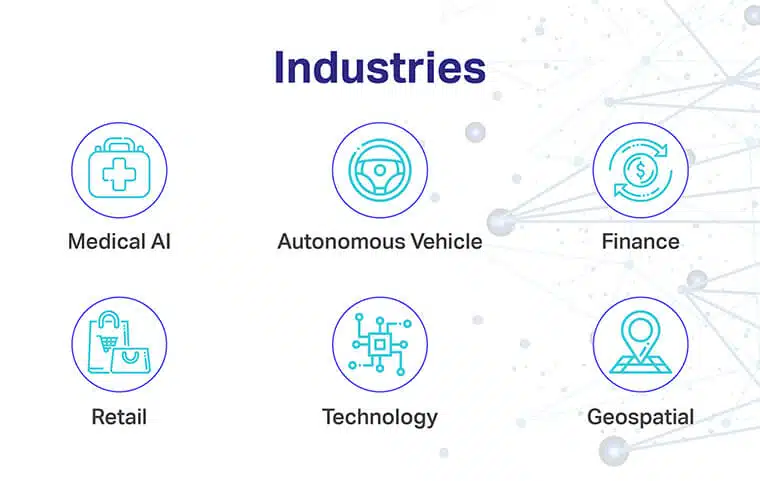
Branże, które są najlepiej obsługiwane przez narzędzia i zasoby do oznaczania danych, obejmują:
- Medyczna sztuczna inteligencja: Obszary zainteresowania obejmują szkolenie modeli diagnostycznych z wizją komputerową w celu poprawy obrazowania medycznego, zminimalizowanie czasu oczekiwania i minimalne zaległości
- Finanse: Obszary zainteresowania obejmują ocenę ryzyka kredytowego, kwalifikowalności pożyczki i innych ważnych czynników za pomocą etykiet tekstowych
- Pojazd autonomiczny lub transport: Obszary zainteresowania obejmują implementację NLP i Computer Vision w celu układania modeli z niesamowitą ilością danych treningowych do wykrywania osób, sygnałów, blokad itp.
- Handel detaliczny i elektroniczny: Obszary zainteresowania obejmują decyzje dotyczące cen, ulepszony e-commerce, monitorowanie osobowości kupującego, zrozumienie nawyków zakupowych i wzmocnienie doświadczenia użytkownika
- Technologia: Obszary zainteresowania obejmują wytwarzanie produktów, pobieranie z pojemników, wykrywanie z wyprzedzeniem krytycznych błędów produkcyjnych i nie tylko
- Geoprzestrzenny: Obszary ostrości obejmują GPS i teledetekcję za pomocą wybranych technik etykietowania
- Rolnictwo: Obszary zainteresowania obejmują wykorzystanie czujników GPS, dronów i wizji komputerowej w celu rozwijania koncepcji rolnictwa precyzyjnego, optymalizacji warunków glebowych i upraw, określania plonów i nie tylko

Nadal nie rozumiem, która strategia jest lepsza, aby zapewnić prawidłowe etykietowanie danych, np. Budowanie samodzielnej konfiguracji lub kupowanie od zewnętrznego dostawcy usług. Oto zalety i wady każdego z nich, które pomogą Ci lepiej decydować:
Podejście „Buduj”
| Budować | Kupić |
|---|---|
Odsłon:
| Odsłon:
|
Misses:
| Misses:
|
Korzyści:
| Korzyści:
|
Werdykt
Jeśli planujesz zbudować ekskluzywny system AI, w którym czas nie będzie stanowił ograniczenia, zbudowanie narzędzia do etykietowania od podstaw ma sens. Do wszystkiego innego najlepszym podejściem jest zakup narzędzia


