

Jakość i dokładność wyników zapewnianych przez system rozpoznawania twarzy i emocji zależy od danych. Im dokładniejsze i bardziej rozbudowane są dane, tym większe są szanse, że program AI będzie w stanie zidentyfikować i wykryć emocje.

Sztuczna inteligencja ma ogromne zalety dla branż ubezpieczeniowych, pod warunkiem, że firmy zrozumieją jej wdrożenie. Usprawnienie zadań takich jak rozpatrywanie roszczeń, ustalanie składek i wykrywanie szkód może również pomóc w obsłudze klienta, zwiększając ogólny poziom zadowolenia.

Deidentyfikacja danych ma kluczowe znaczenie dla ochrony danych osobowych w opiece zdrowotnej, zgodnie z wymogami regulacyjnymi, takimi jak HIPAA i RODO. Prezentowane narzędzia, w tym IBM InfoSphere Optim, Google Healthcare API, AWS Comprehend Medical, Shaip i Private-AI, oferują różnorodne rozwiązania w zakresie skutecznego maskowania danych.

Generatywna sztuczna inteligencja ma kilka zaawansowanych funkcji i funkcjonalności, które pozwalają na modernizację systemów wsparcia obsługi klienta. Tam, gdzie może szybko rozwiązać problemy klienta, generatywna sztuczna inteligencja może również zastąpić agentów w roli osób udzielających pierwszej pomocy i komunikować się z klientami jak człowiek.

Deidentyfikacja danych to kluczowa procedura zapewniająca ochronę przed nieuprawnionym dostępem i niezgodnym z prawem wykorzystaniem danych osobowych. Proces ten, szczególnie ważny w przypadku danych dotyczących opieki zdrowotnej, zapewnia, że żadne informacje umożliwiające identyfikację nie trafią w ręce osób innych niż osoby blisko powiązane z danymi.

Konwersacyjna i generatywna sztuczna inteligencja przekształca nasz świat w wyjątkowy sposób. Konwersacyjna sztuczna inteligencja sprawia, że rozmowa z maszynami jest łatwa i pomocna, poprawiając obsługę klienta i usługi opieki zdrowotnej. Z drugiej strony generatywna sztuczna inteligencja jest kreatywną potęgą. Wynajduje nowe, oryginalne treści w sztuce, muzyce i nie tylko. Zrozumienie tych typów sztucznej inteligencji jest kluczem do podejmowania mądrych decyzji biznesowych, etycznych i innowacyjnych.

Technologie głosowe są wciąż stosunkowo nowymi technologiami i wciąż pracujemy nad dobrym poznaniem oferowanych z nimi rozwiązań. W środowisku opieki zdrowotnej, w którym liczy się czas, wydajność i dokładność mają ogromne znaczenie.

Generatywna sztuczna inteligencja zmienia krajobraz usług bankowych i finansowych, wprowadza wydajność, zwiększa bezpieczeństwo i zapewnia spersonalizowane doświadczenia zarówno klientom, jak i instytucjom. W miarę ciągłego rozwoju technologii jej wpływ na branżę finansową prawdopodobnie będzie wzrastał, rozpoczynając nową erę innowacji i optymalizacji.

Wykorzystanie przetwarzania języka naturalnego (NLP) w służbie zdrowia i przemyśle farmaceutycznym w dużej mierze opiera się na analizie nieustrukturyzowanych danych. Dzięki odpowiednim informacjom organizacje opieki zdrowotnej mogą uzyskać szereg korzyści i zapewnić pacjentom lepsze usługi zdrowotne.

W nadchodzących latach wzrośnie ilość i częstotliwość treści generowanych przez użytkowników. Klienci mają dziś dostęp do innowacyjnych narzędzi, dzięki którym mogą dowiedzieć się wszystkiego o marce. Tam, gdzie dla marki niezbędne jest nawiązanie kontaktu z obecnymi, nowymi i potencjalnymi klientami, monitorowanie i moderowanie treści ma kluczowe znaczenie w tworzeniu pozytywnego wizerunku.

Skuteczne etykietowanie danych jest kluczowym elementem poprawy trafności wyszukiwania. Platformy handlu elektronicznego i firmy odnoszą największe korzyści z etykietowania danych, ponieważ muszą wyświetlać swoje produkty w wynikach wyszukiwania, co prowadzi do wzrostu sprzedaży i przychodów.

Przetwarzanie języka naturalnego (NLP) zapoczątkowało rewolucję w zakresie ekstrakcji i analizy informacji we wszystkich branżach. Wszechstronność tej technologii również ewoluuje, aby dostarczać lepsze rozwiązania i nowe zastosowania. Zastosowanie NLP w finansach nie ogranicza się do zastosowań, które wymieniliśmy powyżej. Z czasem będziemy mogli wykorzystywać tę technologię i jej techniki do jeszcze bardziej skomplikowanych zadań i operacji.

U podstaw zastosowań sztucznej inteligencji w opiece zdrowotnej leżą dane i ich prawidłowa analiza. Wykorzystując te dane i informacje dostarczane przez pracowników służby zdrowia, narzędzia i technologie sztucznej inteligencji mogą dostarczać lepsze rozwiązania w zakresie opieki zdrowotnej pod względem diagnozowania, leczenia, przewidywania, przepisywania leków i obrazowania.

Rozpoznawanie nazwanych jednostek to istotna technika, która toruje drogę do zaawansowanego maszynowego zrozumienia tekstu. Chociaż zbiory danych typu open source mają zalety i wady, odgrywają one zasadniczą rolę w szkoleniu i dostrajaniu modeli NER. Rozsądny wybór i zastosowanie tych zasobów może znacznie podnieść wyniki projektów NLP.

Generatywna sztuczna inteligencja oferuje niezwykłe korzyści, takie jak wydajność, skalowalność i personalizacja, dzięki możliwości tworzenia różnorodnych treści. Jednakże wyzwania takie jak kontrola jakości, ograniczenia kreatywności i kwestie etyczne wymagają szczególnej uwagi.

Generatywna sztuczna inteligencja to ekscytująca granica, która na nowo definiuje granice technologii i kreatywności. Od generowania tekstu przypominającego człowieka po tworzenie realistycznych obrazów, usprawnianie opracowywania kodu, a nawet symulowanie unikalnych wyjść audio – jego rzeczywiste zastosowania są tak różnorodne, jak i transformacyjne.

Zastosowania uczenia maszynowego i sztucznej inteligencji w analizie danych klinicznych są rozległe i przełomowe. Oferują ogromny potencjał w zakresie zmiany sposobu opieki nad pacjentem, usprawnienia badań medycznych oraz zapewnienia wcześniejszej i dokładniejszej diagnozy.

Shaip jest liderem w dostarczaniu najwyższej jakości danych dotyczących opieki zdrowotnej i danych medycznych, które są niezbędne dla modeli sztucznej inteligencji i uczenia maszynowego (ML). Jeśli rozpoczynasz projekt sztucznej inteligencji w opiece zdrowotnej lub potrzebujesz określonych danych medycznych, Shaip jest idealnym partnerem.

Asystenci głosowi nie są już nowością; szybko stają się niezbędne w naszych codziennych interakcjach cyfrowych. Powstanie wielojęzycznego asystenta głosowego zapowiada się jako znaczący krok naprzód, przełamujący bariery językowe i wspierający większą globalną łączność.
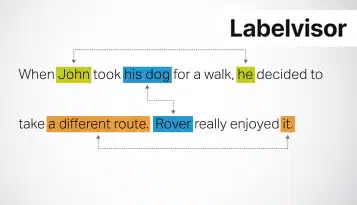
Adnotacje w dokumentach to podstawowy element składowy sztucznej inteligencji, uczenia maszynowego i przetwarzania języka naturalnego. Poprawia możliwości zrozumienia i przetwarzania systemów AI, wspomagając wydajne wydobywanie informacji i wspierając automatyzację w różnych domenach.

Jak zbadaliśmy w powyższych przykładach, analiza nastrojów ma niezwykły potencjał w różnych zastosowaniach, od obsługi klienta po politykę. Umożliwia organizacjom uwolnienie potęgi subiektywnych danych i przekształcenie nieustrukturyzowanego tekstu w praktyczne spostrzeżenia.

Przyszłość sztucznej inteligencji w opiece zdrowotnej jest pełna obietnic i potencjału, a pojawiające się trendy na rok 2023 sygnalizują rewolucyjną zmianę w świadczeniu opieki nad pacjentem.

Przypadki użycia przetwarzania języka naturalnego w opiece zdrowotnej są ogromne i transformujące. Wykorzystując moc sztucznej inteligencji, uczenie maszynowe i konwersacyjną sztuczną inteligencję, NLP rewolucjonizuje sposób, w jaki pracownicy służby zdrowia podchodzą do opieki nad pacjentem. Sprawia, że przepływ pracy medycznej jest bardziej wydajny i poprawia ogólne wyniki pacjentów.
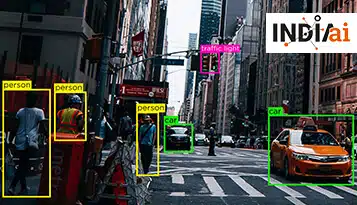
Przyjęcie ekstrakcji jednostek opartej na sztucznej inteligencji doprowadziło do znacznych postępów w różnych branżach, od opieki zdrowotnej po handel elektroniczny, usprawniając podejmowanie decyzji, usprawniając procesy i poprawiając doświadczenia klientów.

Technologia rozpoznawania emocji to potężne narzędzie, które może poprawić nasze zrozumienie ludzkich emocji i pomóc nam tworzyć spersonalizowane doświadczenia w różnych dziedzinach, takich jak opieka zdrowotna, edukacja i marketing.

Ogólnie rzecz biorąc, sektor opieki zdrowotnej jest pełen pacjentów i lekarzy, którzy są zmotywowani, by po raz kolejny zmienić życie ludzi na całym świecie. Dostęp do dużych zbiorów danych jest jednokierunkowy. Sztuczna inteligencja nadal będzie się sprawdzać jako przyszłość medycyny. Zarówno badacze, jak i programiści muszą skorzystać z tych unikalnych zestawów danych, aby lepiej zrozumieć badania kliniczne i opiekę nad pacjentem, gdy zmierzamy w kierunku coraz bardziej połączonej przyszłości dla wszystkich.

Następne pięć lat przyniesie bardziej usprawnione doświadczenia AI, funkcje bezpieczeństwa, które usprawnią te interakcje i nie tylko. Trendy w konwersacyjnej sztucznej inteligencji w ciągu najbliższych kilku lat będą jaśniejsze i bardziej dostępne niż kiedykolwiek wcześniej.

Zmiany są w toku, co prowadzi do bardziej opłacalnej, rentownej przyszłości, która zapewnia lepsze wrażenia użytkownika. Dzięki tym zmianom w połączeniu z możliwością uczenia się na błędach innych firm, sektor BFSI będzie nadal szybko rozwijał się w kierunku wykorzystania rozpoznawania twarzy – skuteczniejszego i bezpieczniejszego celu końcowego dla wszystkich zaangażowanych organów.

Wyszukiwanie głosowe to rozwijająca się dziedzina technologii. Powoli, ale zdecydowanie robi ogromne postępy, ponieważ staje się bardziej wydajny dzięki sztucznej inteligencji, przetwarzaniu języka naturalnego i uczeniu maszynowemu. Rodzaj sztucznej inteligencji, który istnieje teraz, nie jest świadomy; Ci asystenci głosowi to narzędzia, które czynią nasze życie lepszym, prostszym i wydajniejszym.
Usługi etykietowania danych pomagają firmom przekształcać dane, które nie mają etykiet ani tagów, w dane, które je posiadają. Często używają ludzkich grup zadaniowych lub uczenia maszynowego do oznaczania zestawów danych, które przekazują im firmy.

Technologia rozpoznawania głosu może potencjalnie zrewolucjonizować branżę medyczną na kilka sposobów. Umożliwiając szybsze i dokładniejsze dokumentowanie, zmniejszając ryzyko błędów i zwiększając zaangażowanie pacjentów, technologia rozpoznawania głosu może pomóc podmiotom świadczącym opiekę zdrowotną zapewnić lepszą jakość opieki.

Branża ubezpieczeniowa ma wiele danych, ale są one tak zagracone, że wyszukiwanie jest prawie niemożliwe. Branża ubezpieczeniowa musi zostać zdigitalizowana — i teraz jest to możliwe. Dzięki OCR gromadzenie i sortowanie danych staje się tak proste, jak zrobienie zdjęcia lub wpisanie kilku słów.

Banki będą miały pozytywne doświadczenia z wdrażania technologii AI. Opiera się to na wywiadach z firmami, które już wykorzystują sztuczną inteligencję w swoich procesach biznesowych. Dopóki budowane są zabezpieczenia zapewniające bezpieczeństwo danych klientów i standardy etyczne, które można automatycznie regulować, banki powinny wdrażać sztuczną inteligencję do swoich systemów.

Wpływ uczenia maszynowego na rynek call center jest realny i wymierny. Przechwytywanie danych w czasie rzeczywistym i uczenie maszynowe połączyły się, aby zapewnić jeszcze bardziej wydajne call center. Ponadto rozwiązania głosowe wzrosły w całej Ameryce Północnej i nadal rozprzestrzeniają się na całym świecie.

Technologia rozpoznawania głosu staje się coraz ważniejsza w opiece zdrowotnej, a lekarze i pielęgniarki coraz częściej polegają na niej w wykonywaniu wielu swoich obowiązków zawodowych. Chociaż wiele pytań nadal wymaga odpowiedzi, zanim zobaczymy powszechne zastosowanie tej technologii w szpitalach, środowiskach klinicznych i gabinetach lekarskich, wczesne oznaki sugerują znaczną obietnicę.
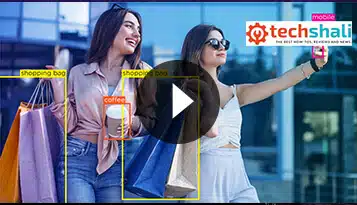
Technologia adnotacji wideo ma na celu zapewnienie bezpieczeństwa detalicznym systemom sztucznej inteligencji i klientom. Oprogramowanie do adnotacji wideo to świetny sposób, aby to zrobić, umożliwiając ludziom szybkie i łatwe powiadamianie władz, gdy są świadkami czegoś podejrzanego w sklepie; pomaganie systemom sztucznej inteligencji uczyć się na podstawie przeszłych doświadczeń, aby mogły dostosować swoje reakcje, aby czuć się lepiej z tym, co jest uważane za normalne zachowanie.

Przypadki użycia rozpoznawania twarzy mogą zdziałać cuda podczas przechowywania i wyszukiwania danych, ale wiążą się również z intrygującym dylematem etycznym. Czy stosowanie takiej technologii ma sens? Niektórzy uważają, że odpowiedź brzmi „nie”, szczególnie w odniesieniu do naruszenia prywatności przez rozpoznawanie twarzy. Inni powołują się na użycie tych nowych narzędzi, dlatego ta technologia może nie być tą, której chcesz unikać za wszelką cenę.

Sztuczna inteligencja zmieni sposób, w jaki wchodzimy w interakcje z technologią. Kiedy już przyzwyczaisz się do konwersacyjnej sztucznej inteligencji i stanie się ona płynną częścią Twojego życia, będziesz się zastanawiać, jak mogłeś się bez niej obejść.

Niestandardowe słowa budzące mogą pomóc w personalizacji Twojej marki i wyróżnić ją na tle konkurencji. Wybierając niestandardowe słowo budzenia, należy wziąć pod uwagę wiele czynników. Ale jeśli chcesz się wyróżnić w dzisiejszym konkurencyjnym świecie biznesu, warto włożyć dodatkowy wysiłek w upewnienie się, że Twój asystent głosowy brzmi wyjątkowo.

Nowe postępy w technologii głosowej już tu zostaną. Będą one nadal zyskiwać na popularności, dzięki czemu teraz jest idealny moment, aby wyprzedzić konkurencję i zacząć tworzyć innowacyjne rozwiązania głosowe dla kierowców. Ponieważ producenci samochodów integrują rozpoznawanie mowy w swoich samochodach, otwiera to nowy świat możliwości dla technologii i jej użytkowników.

Oczywiste jest, że sztuczna inteligencja żywności będzie miała ogromny wpływ na to, jak jemy. Od dążenia sieci fast food do bardziej konfigurowalnych menu po mnóstwo nowych, innowacyjnych restauracji, technologia oferuje niezliczone możliwości uproszczenia naszych doświadczeń żywieniowych i poprawy jakości naszego jedzenia. Wraz z rozwojem sztucznej inteligencji i algorytmów uczenia maszynowego możemy oczekiwać, że inteligentna sztuczna inteligencja żywności pozytywnie wpłynie na nasze zdrowie i ogólny wpływ ekologiczny naszego systemu żywnościowego.

Podsumowując, segmentacja semantyczna jest ważnym sektorem algorytmów głębokiego uczenia, które mają na celu przyspieszenie postępów w wizji komputerowej. Segmentacja semantyczna będzie postępowała w wielu z tych powiązanych podkategorii, wykrywaniu obiektów, klasyfikacji i lokalizacji.

Ogólnie rzecz biorąc, skuteczny system rozpoznawania mowy powinien być łatwy do skonfigurowania i używania w różnych sytuacjach, przy jednoczesnym osiąganiu dokładnych wyników przy niewielkiej frustracji ze strony użytkownika.

Budowanie danych inteligentnego domu wymaga zestawu procesów, które ostatecznie zapewniają, że algorytm uczenia maszynowego działa i przetwarza dane bez zakłóceń.

Branża ubezpieczeniowa była tradycyjnie konserwatywna w związku z postępem technologicznym i niechętnie przyjmowała nowe technologie. Jednak czasy się zmieniają, a sztuczna inteligencja (AI) zyskuje coraz większe zainteresowanie firm ubezpieczeniowych, które zaczynają zdawać sobie sprawę z ważnej roli, jaką AI może odgrywać w ich działaniach.

Zbieranie danych to proces gromadzenia, analizowania i mierzenia dokładnych danych z różnych systemów, które są wykorzystywane do podejmowania decyzji dotyczących procesów biznesowych, projektów dotyczących mowy i badań.

Bankowość nie jest już tym, czym była. Większość z nas potrzebuje szybkich, wydajnych, bezbłędnych usług bankowych, które są bezproblemowe i, co najważniejsze, niezawodne. Sensowne jest tylko przejście na cyfrowe kanały bankowe, które mogą zapewnić te rzeczy. Jak się okazuje, wirtualni asystenci zasilani sztuczną inteligencją (AI) i uczeniem maszynowym (ML) mogą właśnie to zrobić.

Czy kiedykolwiek musiałeś tłumaczyć ważne e-maile na inny język? Jeśli tak, to frustruje Cię świadomość, że czyjaś usługa poczty e-mail nie może szybko przetłumaczyć Twoich e-maili. Może to być szczególnie frustrujące, jeśli komunikacja jest kluczowa dla każdej organizacji.

Terminy chatbot i wirtualni asystenci są używane do tworzenia rozmów z wykorzystaniem możliwości automatyzacji z ludzkim dotykiem. Dzięki autonomicznej rozdzielczości chatboty i wirtualni asystenci przyspieszają również obsługę pracowników i klientów.

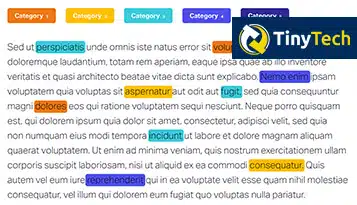
Często uważana za jedną z poddziedzin klasyfikacji tekstu, uproszczona wersja klasyfikacji dokumentów oznacza oznaczanie dokumentów i ustawianie ich w predefiniowanych kategoriach – w celu łatwej konserwacji i wydajnego wyszukiwania.

Hej Siri, czy możesz mnie poszukać dobrego wpisu na blogu, który zawiera najważniejsze trendy w konwersacyjnej sztucznej inteligencji. Albo, Alexa, możesz po prostu zagrać mi piosenkę, która odciągnie mój umysł od przyziemnych codziennych zadań. Cóż, to nie tylko retoryka, ale standardowe dyskusje w salonie, które potwierdzają ogólny wpływ koncepcji zwanej konwersacyjną sztuczną inteligencją.

OCR lub optyczne rozpoznawanie znaków to świetny sposób na czytanie i rozumienie dokumentów. Ale dlaczego to ma sens? Dowiedzmy Się. Ale zanim przejdziemy dalej, musimy zastanowić się nad mniej popularnym terminem uczenia maszynowego: RPA (Robotic Process Automation).

Trudna prawda jest taka, że jakość zebranych danych treningowych determinuje jakość Twojego modelu rozpoznawania mowy, a nawet urządzenia. Dlatego konieczne jest skontaktowanie się z doświadczonymi dostawcami danych, aby pomóc Ci przejść przez proces bez większego wysiłku, zwłaszcza gdy uczenie modelu lub odpowiednich algorytmów wymaga gromadzenia, adnotacji i innych umiejętnych strategii.

Umiejętność wszczepiona maszynom – czyniąca je zdolnymi do interakcji w najbardziej humanitarny możliwy sposób – ma inny rodzaj haju. Pozostaje jednak pytanie, jak konwersacyjna sztuczna inteligencja działa w czasie rzeczywistym i jaki rodzaj technologii napędza jego istnienie.

Jak sama nazwa wskazuje, dane syntetyczne to dane, które są generowane sztucznie, a nie tworzone przez rzeczywiste zdarzenia. W marketingu, mediach społecznościowych, opiece zdrowotnej, finansach i bezpieczeństwie dane syntetyczne pomagają tworzyć bardziej innowacyjne rozwiązania.

Kiedy mówimy o optycznym rozpoznawaniu znaków (OCR), jest to dziedzina sztucznej inteligencji (AI), która jest szczególnie związana z widzeniem komputerowym i rozpoznawaniem wzorców. OCR odnosi się do procesu wydobywania informacji z wielu formatów danych, takich jak obrazy, pdf, odręczne notatki i zeskanowane dokumenty, i konwertowania ich do formatu cyfrowego w celu dalszego przetwarzania.

System monitorowania kierowcy to zaawansowana funkcja bezpieczeństwa, która wykorzystuje kamerę zamontowaną na desce rozdzielczej do monitorowania czujności i senności kierowcy. W przypadku, gdy kierowca jest śpiący i roztargniony, system monitorowania kierowcy generuje ostrzeżenie i zaleca zrobienie sobie przerwy.

Przetwarzanie języka naturalnego to poddziedzina sztucznej inteligencji zdolna do przełamania ludzkiego języka i przekazania jego zasad inteligentnym modelom. Czy planujesz użyć NLP jako technologii treningu modelowego? Czytaj dalej, aby poznać wyzwania i rozwiązania, aby je naprawić.

Ponadto konwersacyjna sztuczna inteligencja stale uczy się na podstawie wcześniejszych doświadczeń, korzystając z zestawów danych uczenia maszynowego, aby oferować wgląd w czasie rzeczywistym i doskonałą obsługę klienta. Ponadto konwersacyjna sztuczna inteligencja nie tylko ręcznie rozumie nasze zapytania i odpowiada na nie, ale może być również połączona z innymi technologiami sztucznej inteligencji, takimi jak wyszukiwanie i wizja, w celu przyspieszenia procesu.

Rozpoznawanie obrazów to zdolność oprogramowania do identyfikowania obiektów, miejsc, ludzi i działań na obrazach. Korzystając z zestawów danych uczenia maszynowego, przedsiębiorstwa mogą używać rozpoznawania obrazów do identyfikowania i klasyfikowania obiektów na kilka kategorii.

Sztuczna inteligencja sprawia, że maszyny są mądrzejsze, kropka! Jednak sposób, w jaki to robią, jest tak samo inny i intrygujący, jak dany pion. Na przykład, przetwarzanie języka naturalnego przydaje się, gdy projektujesz i rozwijasz dowcipne chatboty i cyfrowych asystentów. Podobnie, jeśli chcesz, aby sektor ubezpieczeń był bardziej przejrzysty i przychylny dla użytkowników, Computer Vision jest subdomeną AI, na której musisz się skupić.

Czy maszyny mogą wykrywać emocje po prostu skanując twarz? Dobrą wiadomością jest to, że mogą. A złą wiadomością jest to, że przed rynkiem wciąż jest daleka droga, zanim stanie się głównym nurtem. Jednak przeszkody i wyzwania związane z adopcją nie powstrzymują ewangelistów AI przed umieszczaniem „Wykrywania emocji” na mapie AI – dość agresywnie.

Widzenie komputerowe nie jest tak rozpowszechnione, jak inne aplikacje AI, takie jak przetwarzanie języka naturalnego. Jednak powoli rośnie w rankingach, dzięki czemu rok 2022 jest ekscytującym rokiem dla adopcji na większą skalę. Oto niektóre z modnych potencjałów wizji komputerowej (głównie domen), które mają być lepiej eksplorowane przez firmy w 2022 roku.

Przedsiębiorstwa na całym świecie przechodzą z dokumentów papierowych na cyfrowe przetwarzanie danych. Ale czym jest OCR? Jak to działa? A w jakim procesie biznesowym można go wykorzystać, aby wykorzystać jego zalety? Przyjrzyjmy się temu artykułowi, jakie korzyści przynosi OCR.

Odpowiedzią jest automatyczne rozpoznawanie mowy (ASR). Przekształcenie słowa mówionego w formę pisemną to ogromny krok. Automatyczne rozpoznawanie mowy (ASR) to trend, który będzie hałasował w 2022 roku. Wzrost liczby asystentów głosowych jest spowodowany wbudowanymi smartfonami z asystentami głosowymi i inteligentnymi urządzeniami głosowymi, takimi jak Alexa.
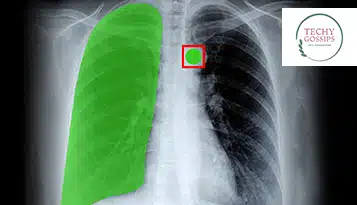
Szukasz mózgu stojącego za najlepszymi modelami sztucznej inteligencji? Cóż, kłaniaj się adnotatorom danych. Mimo że adnotacje do danych zajmują centralne miejsce w przygotowywaniu zasobów odpowiednich dla każdej branży opartej na sztucznej inteligencji, zbadamy tę koncepcję i dowiemy się więcej o bohaterach etykietowania z perspektywy AI w opiece zdrowotnej.

I czy nie uważasz za fascynujące, że kupujący płacą rachunek przy kasie, przedstawiając twarz, a nie kartę lub portfel? Rozpoznawanie twarzy pozwala sprzedawcom analizować nastroje i preferencje kupujących na podstawie ich wcześniejszych zakupów.

W związku z rosnącą liczbą płatności cyfrowych dokonywanych na całym świecie, w jaki sposób organizacje finansowe mogą zapewnić maksymalną konwersję sprzedaży i akceptację płatności, a także zminimalizować ryzyko? Brzmi niepokojąco? W branży finansowej, która jest wysoce uzależniona od przetwarzania danych i informacji utrzymujących marginalną przewagę i rozumiejących naturalne niuanse klientów w celu zapewnienia terminowego rozwiązywania problemów, wymagana jest technologia związana z AI.

Drony są realnym narzędziem do zbierania danych i dostarczają informacji w czasie rzeczywistym. Korzystanie z analizy danych umożliwia łatwiejsze sprawdzanie mostów, wydobycie i prognozowanie pogody.

Analiza sentymentu Call Center polega na przetwarzaniu danych poprzez identyfikowanie naturalnych niuansów kontekstu klienta i analizowanie danych, aby obsługa klienta była bardziej empatyczna.

Cóż, pierwszy powód nie wymaga potwierdzenia. Projekty uczenia maszynowego wymagają algorytmów, pozyskiwania danych, wysokiej jakości adnotacji i innych złożonych aspektów, o które zadbano.

Jako gałąź sztucznej inteligencji, NLP polega na tym, aby maszyny odpowiadały na ludzki język. Przechodząc do aspektu technicznego, NLP, całkiem słusznie, wykorzystuje informatykę, lingwistykę, algorytmy i ogólną strukturę języka, aby uczynić maszyny inteligentnymi. Proaktywne i intuicyjne maszyny, kiedy tylko zostaną zbudowane, mogą wyodrębnić, analizować i rozumieć prawdziwe znaczenie i kontekst z mowy, a nawet tekstu.

W tym miejscu Medical Image Adnotation ma do odegrania rolę, ponieważ skutecznie przekazuje niezbędną wiedzę medycznym konfiguracjom diagnostycznym opartym na sztucznej inteligencji w celu zwiększenia obecności dokładnego widzenia komputerowego, jako podstawowej technologii opracowywania modeli.

Sztuczna inteligencja nie musi być ponurym tematem do dyskusji. Pełna możliwości stania się najbardziej transformacyjnym narzędziem w nadchodzących latach, sztuczna inteligencja szybko przekształca się w zasób pomocniczy, zamiast pozostać na kursie jako przytłaczająca technologia.

Czy znasz szczegóły techniczne związane z tworzeniem holistycznych, intuicyjnych i skutecznych modeli uczenia maszynowego? Jeśli nie, najpierw musisz zrozumieć, w jaki sposób każdy proces jest ogólnie podzielony na trzy fazy, tj. Zabawa, Funkcjonalność i Finezja. Podczas gdy „Finesse” dotyczy doskonalenia algorytmów ML poprzez tworzenie najpierw złożonych programów przy użyciu odpowiednich języków programowania, część „Zabawa” polega na uszczęśliwianiu klientów poprzez oferowanie im spostrzegawczego i inteligentnego produktu do zabawy.

Wyobraź sobie, że budzisz się pewnego pięknego dnia i widzisz wszystkie swoje kuchenne pojemniki na rynku w kolorze czarnym, oślepiając Cię na to, co jest w środku. A potem znalezienie kostek cukru do herbaty będzie wyzwaniem. Pod warunkiem, że najpierw znajdziesz herbatę.

Adnotacja danych to po prostu proces oznaczania informacji, aby maszyny mogły z nich korzystać. Jest to szczególnie przydatne w przypadku nadzorowanego uczenia maszynowego (ML), w którym system opiera się na oznaczonych zestawach danych w celu przetwarzania, rozumienia i uczenia się na podstawie wzorców wejściowych w celu uzyskania pożądanych wyników.

Etykietowanie danych nie jest wcale takie trudne, jak mówi żadna organizacja! Jednak pomimo wyzwań po drodze, niewielu zdaje sobie sprawę z wymagającego charakteru stojących przed nimi zadań. Etykietowanie zbiorów danych, zwłaszcza w celu dostosowania ich do modeli sztucznej inteligencji i uczenia maszynowego, wymaga wieloletniego doświadczenia i praktycznej wiarygodności. Co więcej, oznaczanie danych nie jest podejściem jednowymiarowym i różni się w zależności od typu modelu w pracy.

Pozyskiwanie danych do projektów mowy jest uproszczone, jeśli zastosujesz podejście systematyczne. Przeczytaj nasz ekskluzywny post na temat pozyskiwania danych do projektów mowy i uzyskaj przejrzystość.

W prostych słowach adnotacja tekstowa polega na oznaczaniu etykietami określonych dokumentów, plików cyfrowych, a nawet powiązanych treści. Gdy te zasoby zostaną otagowane lub opatrzone etykietą, stają się zrozumiałe i mogą zostać wdrożone przez algorytmy uczenia maszynowego w celu wytrenowania modeli do perfekcji.

Dzisiaj wybraliśmy Vatsala Ghiyę do przeprowadzenia wywiadu. Vatsal Ghiya jest seryjnym przedsiębiorcą z ponad 20-letnim doświadczeniem w oprogramowaniu i usługach AI w służbie zdrowia. Jest prezesem i współzałożycielem firmy Shaip, która umożliwia skalowanie na żądanie naszej platformy, procesów i ludzi dla firm z najbardziej wymagającymi inicjatywami uczenia maszynowego i sztucznej inteligencji.

Usługi finansowe z biegiem czasu uległy metamorfozie. Gwałtowny wzrost płatności mobilnych, rozwiązań bankowości osobistej, lepszego monitorowania kredytów i innych wzorców finansowych dodatkowo zapewnia, że sfera dotycząca wtrąceń monetarnych nie jest tym, czym była kilka lat temu. W 2021 r. nie chodzi tylko o „Fin” lub finanse, ale o wszystkie „FinTech” z przełomowymi technologiami finansowymi, które sprawiają, że ich obecność jest odczuwalna, aby zmienić wrażenia klientów, sposób działania odpowiednich organizacji, a dokładniej całą arenę fiskalną.
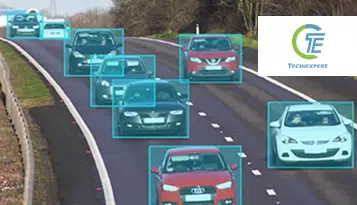
Pomimo szybkiego rozwoju przemysłu motoryzacyjnego, pion pozostawia wiele możliwości dla stopniowych ulepszeń. Począwszy od zmniejszania liczby wypadków drogowych po poprawę produkcji pojazdów i wdrażania zasobów, sztuczna inteligencja wydaje się najbardziej prawdopodobnym rozwiązaniem, które sprawi, że sprawy poruszą się w górę.

Sztuczna inteligencja wydaje się obecnie bardziej żargonem marketingowym. Każda firma, startup lub firma, którą znasz, promuje swoje produkty i usługi, używając jako USP terminu „zasilane sztuczną inteligencją”. Zgodnie z tym, sztuczna inteligencja z pewnością wydaje się w dzisiejszych czasach nieunikniona. Jeśli zauważysz, prawie wszystko, co masz wokół siebie, jest zasilane przez sztuczną inteligencję. Od silników rekomendacji na Netflix i algorytmów w aplikacjach randkowych po niektóre z najbardziej złożonych podmiotów w sektorze opieki zdrowotnej, które pomagają w onkologii, sztuczna inteligencja znajduje się dziś w centrum wszystkiego.

Uczenie maszynowe ma prawdopodobnie najbardziej mieszane definicje i interpretacje na świecie. To, co pojawiło się jako modne hasło kilka lat temu, nadal wprawia w zakłopotanie wiele osób ze względu na sposób, w jaki zostało przedstawione i zaprezentowane.

Sztuczna inteligencja (AI) jest ambitna i niezwykle korzystna dla rozwoju ludzkości. W takiej przestrzeni jak opieka zdrowotna, szczególnie sztuczna inteligencja przynosi niezwykłe zmiany w sposobie podejścia do diagnozowania chorób, ich leczenia, opieki nad pacjentem i monitorowania pacjenta. Nie należy zapominać o badaniach i rozwoju związanych z opracowywaniem nowych leków, nowszych sposobów odkrywania obaw i przyczyn leżących u ich podstaw i nie tylko.

Opieka zdrowotna, jako pion, nigdy nie była statyczna. Ale z drugiej strony, nigdy nie było tak dynamiczne, z konfluencją odmiennych spostrzeżeń medycznych, co sprawia, że bezruchowo patrzymy na stosy nieustrukturyzowanych danych. Szczerze mówiąc, gigantyczna ilość danych nie stanowi już problemu. To rzeczywistość, która do końca 2,000 roku przekroczyła nawet granicę 2020 eksabajtów.

Sztuczna inteligencja to technologia, która umożliwia maszynom naśladowanie ludzkich zachowań. Chodzi o nauczenie maszyn, jak uczyć się i myśleć autonomicznie oraz wykorzystywać wyniki, aby odpowiednio reagować i reagować.

Za każdym razem, gdy Twój system nawigacji GPS poprosi Cię o objazd, aby uniknąć korków, zdaj sobie sprawę, że tak dokładna analiza i wyniki pojawiają się po kilkuset godzinach treningu. Zawsze, gdy aplikacja Google Lens dokładnie identyfikuje obiekt lub produkt, pamiętaj, że jej moduł AI (sztucznej inteligencji) przetworzył tysiące zdjęć w celu dokładnej identyfikacji.

4 podstawowe rzeczy, które należy wiedzieć o dezidentyfikacji danych Przy generowaniu danych z szybkością 2.5 trylionów bajtów każdego dnia, my, jako użytkownicy Internetu, generowaliśmy w 1.7 r. prawie 2020 MB co sekundę.

Teraz, gdy cała planeta jest online i połączona, wspólnie generujemy niezmierzone ilości danych. Branża, firma, segment rynku lub jakakolwiek inna jednostka postrzegałaby dane jako pojedynczą jednostkę. Mimo to, jeśli chodzi o osoby fizyczne, dane są lepiej określane jako nasz cyfrowy ślad.

Wysokiej jakości dane przekładają się na historie sukcesu, podczas gdy słaba jakość danych to dobre studium przypadku. Niektóre z najbardziej znaczących studiów przypadku dotyczących funkcjonalności sztucznej inteligencji wynikają z braku wysokiej jakości zbiorów danych. Podczas gdy wszystkie firmy są podekscytowane i ambitne w odniesieniu do swoich przedsięwzięć i produktów związanych z AI, podekscytowanie nie ma odzwierciedlenia w zbieraniu danych i praktykach szkoleniowych. Koncentrując się bardziej na produkcji niż na szkoleniu, niektóre firmy opóźniają swój czas wprowadzania produktów na rynek, tracą fundusze, a nawet zamykają rolety na wieczność.

Proces dodawania adnotacji lub tagowania wygenerowanych danych, który pozwala algorytmom uczenia maszynowego i sztucznej inteligencji na skuteczne identyfikowanie każdego typu danych i decydowanie, czego się z nich nauczyć i co z nimi zrobić. Im lepiej zdefiniowany lub oznaczony jest każdy zestaw danych, tym lepiej algorytmy mogą go przetwarzać w celu uzyskania zoptymalizowanych wyników.
Alexa, czy w pobliżu mnie jest miejsce na sushi? Często zadajemy naszym wirtualnym asystentom pytania otwarte. Zadawanie takich pytań innym ludziom jest zrozumiałe, biorąc pod uwagę, że w ten sposób jesteśmy przyzwyczajeni do mówienia i interakcji. Jednak zadawanie potocznie bardzo przypadkowego pytania maszynie, która prawie nie ma pojęcia o języku i zawiłościach konwersacyjnych, nie ma sensu?

Cóż, za każdym tak zaskakującym incydentem kryją się koncepcje takie jak sztuczna inteligencja, uczenie maszynowe i co najważniejsze, NLP (przetwarzanie języka naturalnego). Jednym z największych przełomów naszych ostatnich czasów jest NLP, w którym maszyny stopniowo ewoluują, aby zrozumieć, jak ludzie mówią, emotują, rozumieją, reagują, analizują, a nawet naśladują ludzkie rozmowy i zachowania oparte na sentymentach. Koncepcja ta wywarła duży wpływ na rozwój chatbotów, narzędzi zamiany tekstu na mowę, rozpoznawania głosu, wirtualnych asystentów i nie tylko. .

Pomimo tego, że jest to koncepcja wprowadzona w latach pięćdziesiątych, sztuczna inteligencja (AI) nie stała się powszechnie znana dopiero kilka lat temu. Ewolucja sztucznej inteligencji była stopniowa i zajęło prawie sześć dekad, zanim zaoferowano jej szalone funkcje i funkcje, które ma dzisiaj. Wszystko to było niezwykle możliwe dzięki jednoczesnej ewolucji urządzeń peryferyjnych, infrastruktur technologicznych, pokrewnych koncepcji, takich jak przetwarzanie w chmurze, systemy przechowywania i przetwarzania danych (Big Data i analityka), penetracja i komercjalizacja Internetu i wiele innych. Wszystko razem doprowadziło do tej niesamowitej fazy technologicznej osi czasu, w której sztuczna inteligencja i uczenie maszynowe (ML) nie tylko napędzają innowacje, ale także stają się nieuniknionymi koncepcjami, bez których można żyć.

Każdy system AI potrzebuje ogromnych ilości wysokiej jakości danych, aby trenować i dostarczać dokładne wyniki. Teraz w tym zdaniu są dwa słowa kluczowe - ogromne ilości i wysokiej jakości dane. Omówmy oba indywidualnie.

Wszystkie dotychczasowe rozmowy i dyskusje na temat wdrażania sztucznej inteligencji do celów biznesowych i operacyjnych były tylko powierzchowne. Niektórzy mówią o korzyściach z ich wdrożenia, podczas gdy inni dyskutują o tym, jak moduł AI może zwiększyć produktywność o 40%. Ale nie zajmujemy się prawdziwymi wyzwaniami związanymi z włączeniem ich do naszych celów biznesowych.
Trudno wyobrazić sobie walkę z globalną pandemią bez technologii takich jak sztuczna inteligencja (AI) i uczenie maszynowe (ML). Wykładniczy wzrost przypadków Covid-19 na całym świecie sparaliżował wiele infrastruktur medycznych. Jednak instytucje, rządy i organizacje były w stanie walczyć z pomocą zaawansowanych technologii. Sztuczna inteligencja i uczenie maszynowe, niegdyś postrzegane jako luksus dla podwyższonego stylu życia i produktywności, stały się środkami ratującymi życie w walce z Covid dzięki ich niezliczonym zastosowaniom.

Ból jest intensywniej odczuwany w pewnych grupach ludzi. Badania wykazały, że osoby z grup mniejszościowych i znajdujących się w niekorzystnej sytuacji mają tendencję do odczuwania większego bólu fizycznego niż populacja ogólna z powodu stresu, ogólnego stanu zdrowia i innych czynników.

Zanim jeszcze zaplanujesz pozyskiwanie danych, jeden z najważniejszych czynników decydujących o tym, ile powinieneś wydać na dane treningowe AI. W tym artykule przedstawimy Ci wgląd w opracowanie efektywnego budżetu na dane szkoleniowe AI.

Shaip to platforma internetowa, która koncentruje się na rozwiązaniach z zakresu AI w zakresie opieki zdrowotnej i oferuje licencjonowane dane dotyczące opieki zdrowotnej, które mają pomóc w konstruowaniu modeli AI. Dostarcza tekstową dokumentację medyczną pacjenta i dane roszczeń, dźwięk, taki jak nagrania lekarzy lub rozmowy pacjenta/lekarza, oraz obrazy i wideo w postaci zdjęć rentgenowskich, tomografii komputerowej i wyników MRI.

Dane są jednym z najważniejszych elementów w rozwoju algorytmu AI. Pamiętaj, że tylko dlatego, że dane są generowane szybciej niż kiedykolwiek wcześniej, nie oznacza to, że łatwo jest znaleźć właściwe dane. Dane niskiej jakości, stronnicze lub niepoprawnie opatrzone adnotacjami mogą (w najlepszym przypadku) dodać kolejny krok. Te dodatkowe kroki spowalniają pracę, ponieważ zespoły zajmujące się analizą danych i programistami muszą je przepracować w drodze do funkcjonalnej aplikacji.

Wiele zrobiono na temat potencjału sztucznej inteligencji w przekształcaniu branży opieki zdrowotnej i nie bez powodu. Wyrafinowane platformy AI są zasilane danymi, a organizacje opieki zdrowotnej mają ich pod dostatkiem. Dlaczego więc branża pozostaje w tyle za innymi pod względem przyjęcia sztucznej inteligencji? To wieloaspektowe pytanie z wieloma możliwymi odpowiedziami. Wszystkie z nich jednak bez wątpienia będą podkreślać w szczególności jedną przeszkodę: duże ilości nieustrukturyzowanych danych.

Jednak to, co wydaje się proste, jest żmudne w opracowywaniu i wdrażaniu, jak każdy inny złożony system sztucznej inteligencji. Zanim urządzenie mogło rozpoznać przechwycony obraz, a moduły uczenia maszynowego (ML) mogły go przetworzyć, adnotator danych lub ich zespół spędziłby tysiące godzin na dodawaniu adnotacji do danych, aby były zrozumiałe dla maszyn.

W tej specjalnej funkcji dla gości Vatsal Ghiya, dyrektor generalny i współzałożyciel firmy Shaip, bada trzy czynniki, które jego zdaniem pozwolą na wykorzystanie pełnego potencjału sztucznej inteligencji opartej na danych w przyszłości: talent i zasoby niezbędne do konstruowania innowacyjnych algorytmów, ogromna ilość danych, aby dokładnie wytrenować te algorytmy, i duża moc obliczeniowa, aby skutecznie wydobywać te dane. Vatsal jest seryjnym przedsiębiorcą z ponad 20-letnim doświadczeniem w oprogramowaniu i usługach AI w służbie zdrowia. Shaip umożliwia skalowanie na żądanie swojej platformy, procesów i ludzi dla firm z najbardziej wymagającymi inicjatywami uczenia maszynowego i sztucznej inteligencji.

Procesy w systemach sztucznej inteligencji (AI) są ewolucyjne. W przeciwieństwie do innych produktów, usług lub systemów dostępnych na rynku, modele AI nie oferują natychmiastowych przypadków użycia ani natychmiastowych 100% dokładnych wyników. Wyniki ewoluują wraz z większym przetwarzaniem odpowiednich i jakościowych danych. To tak, jak dziecko uczy się mówić lub jak muzyk zaczyna od nauki pierwszych pięciu akordów durowych, a następnie buduje na nich. Osiągnięcia nie są odblokowywane z dnia na dzień, ale trening odbywa się konsekwentnie, aby osiągnąć doskonałość.

Ilekroć mówimy o sztucznej inteligencji (AI) i uczeniu maszynowym (ML), od razu wyobrażamy sobie potężne firmy technologiczne, wygodne i futurystyczne rozwiązania, fantazyjne autonomiczne samochody i w zasadzie wszystko, co jest estetyczne, kreatywne i intelektualnie przyjemne. To, co prawie nie jest widoczne dla ludzi, to prawdziwy świat kryjący się za wszystkimi udogodnieniami i doświadczeniami stylu życia oferowanymi przez sztuczną inteligencję.

Ekskluzywny wywiad, w którym Utsav, Business Head - Shaip, rozmawia z Sunilem, redaktorem wykonawczym My Startup, aby poinformować go o tym, jak Shaip ulepsza ludzkie życie, rozwiązując problemy przyszłości dzięki oferowanym przez nią Conversational AI i Healthcare AI. Dalej stwierdza, w jaki sposób AI, ML ma zrewolucjonizować sposób, w jaki prowadzimy działalność biznesową i jak Shaip przyczyni się do rozwoju technologii nowej generacji. .
Sztuczna inteligencja (AI) ulepsza nasz styl życia dzięki lepszym rekomendacjom filmów, sugestiom restauracji, rozwiązywaniu konfliktów za pomocą chatbotów i nie tylko. Siła, potencjał i możliwości sztucznej inteligencji są coraz częściej wykorzystywane w różnych branżach i obszarach, o których prawdopodobnie nikt nie pomyślał. W rzeczywistości sztuczna inteligencja jest badana i wdrażana w takich obszarach, jak opieka zdrowotna, handel detaliczny, bankowość, wymiar sprawiedliwości w sprawach karnych, nadzór, zatrudnianie, naprawianie luk płacowych i innych.

Wszyscy widzieliśmy, co się dzieje, gdy rozwój AI idzie nie tak. Rozważmy próbę Amazona stworzenia systemu rekrutacji AI, który był świetnym sposobem na skanowanie życiorysów i identyfikację najlepiej wykwalifikowanych kandydatów — pod warunkiem, że byli to mężczyźni.

Branża opieki zdrowotnej została wystawiona na próbę w zeszłym roku z powodu pandemii i pojawiło się wiele innowacji — od nowych leków i urządzeń medycznych po przełomy w łańcuchu dostaw i lepsze procesy współpracy. Liderzy biznesu ze wszystkich obszarów branży znaleźli nowe sposoby na przyspieszenie wzrostu, aby wspierać wspólne dobro i generować krytyczne dochody.

Widzieliśmy je w filmach, czytaliśmy o nich w książkach i doświadczyliśmy ich w prawdziwym życiu. Choć może się to wydawać sci-fi, musimy zmierzyć się z faktami – rozpoznawanie twarzy nie zniknie. Technologia rozwija się w dynamicznym tempie, a różnorodność zastosowań, które pojawiają się w różnych branżach, sprawia, że szeroki zakres rozwoju rozpoznawania twarzy wydaje się po prostu nieunikniony i nieskończony.

Wielojęzyczne chatboty zmieniają świat biznesu. Chatboty przeszły długą drogę od swoich wczesnych etapów, na których udzielały prostych odpowiedzi jednowyrazowych. Chatbot może teraz płynnie rozmawiać w dziesiątkach języków, umożliwiając firmom ekspansję na szerszy globalny rynek.

Opieka zdrowotna jest często postrzegana jako branża będąca w czołówce innowacji technologicznych. To prawda na wiele sposobów, ale przestrzeń opieki zdrowotnej jest również ściśle regulowana przez szeroko zakrojone przepisy, takie jak RODO i HIPAA, wraz z wieloma innymi lokalnymi wytycznymi i ograniczeniami.

Raport z 2018 r. wykazał, że każdego dnia generowaliśmy blisko 2.5 tryliona bajtów danych. Wbrew powszechnemu przekonaniu nie wszystkie generowane przez nas dane mogą być przetwarzane w celu uzyskania wglądu.

Sztuczna inteligencja z dnia na dzień staje się coraz mądrzejsza. Obecnie potężne algorytmy uczenia maszynowego są w zasięgu normalnych firm, a algorytmy wymagające mocy obliczeniowej, która kiedyś była zarezerwowana dla ogromnych komputerów mainframe, można teraz wdrażać na niedrogich serwerach w chmurze. .