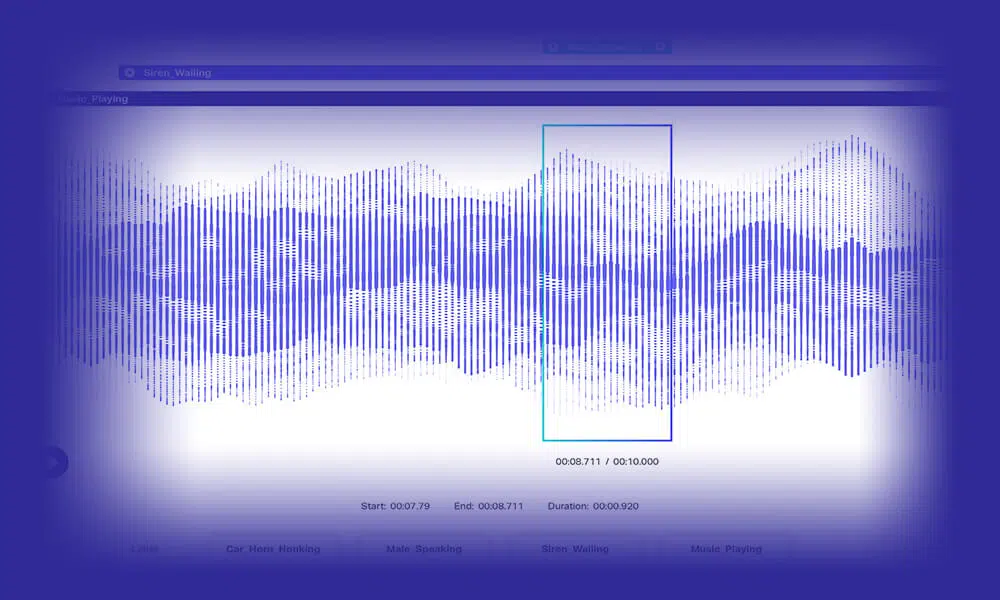


Transkrypcja audio
Opracuj inteligentne modele NLP, dostarczając mnóstwo precyzyjnie przepisanych danych mowy/dźwięku. W Shaip umożliwiamy Ci wybór z szerszego zestawu opcji, w tym standardowego dźwięku, dosłownej i wielojęzycznej transkrypcji. Dodatkowo możesz trenować modele za pomocą dodatkowych identyfikatorów głośników i danych znaczników czasu.
Etykietowanie mowy
Etykietowanie mowy lub dźwięku to standardowa technika adnotacji, która dotyczy oddzielania dźwięków i oznaczania określonymi metadanymi. Istota tej techniki polega na identyfikacji ontologicznej dźwięków z fragmentu audio i dokładnym opisaniu ich, aby zbiory danych treningowych były bardziej inkluzywne

Klasyfikacja dźwięku
Jest używany przez firmy zajmujące się adnotacjami mowy do perfekcyjnego szkolenia AI, dotyczy analizy nagrań audio, zgodnie z treścią. Dzięki klasyfikacji dźwiękowej maszyny mogą identyfikować głosy i dźwięki, jednocześnie będąc w stanie je rozróżnić, w ramach bardziej proaktywnego reżimu treningowego.

Wielojęzyczne usługi danych audio
Zbieranie wielojęzycznych danych dźwiękowych jest przydatne tylko wtedy, gdy adnotatorzy mogą je odpowiednio oznaczyć i podzielić na segmenty. Tutaj przydają się wielojęzyczne usługi danych dźwiękowych, ponieważ dotyczą one adnotacji mowy w oparciu o różnorodność języka, które mają być doskonale identyfikowane i analizowane przez odpowiednie AI

Język naturalny
Wypowiedź
NLU dotyczy adnotacji ludzkiej mowy w celu sklasyfikowania najmniejszych szczegółów, takich jak semantyka, dialekty, kontekst, stres i inne. Ta forma danych z adnotacjami ma sens w lepszym szkoleniu wirtualnych asystentów i chatbotów.
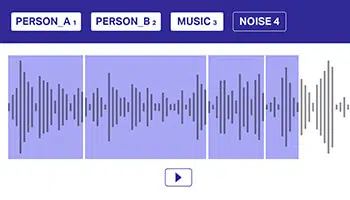
Wiele etykiet
Adnotacja
Adnotowanie danych dźwiękowych poprzez odwoływanie się do wielu etykiet jest ważne, aby pomóc modelom w rozróżnianiu nakładających się źródeł dźwięku. W tym podejściu zestaw danych audio może należeć do jednej lub wielu klas, które muszą być wyraźnie przekazane do modelu w celu lepszego podejmowania decyzji.

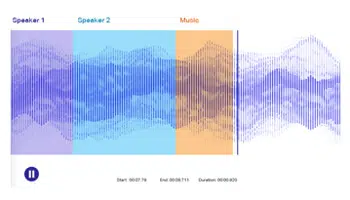
Diaryzacja mówcy
Polega na podzieleniu wejściowego pliku audio na jednorodne segmenty związane z poszczególnymi głośnikami. Diaryzacja oznacza identyfikowanie granic głośników i grupowanie plików audio w segmenty w celu określenia liczby różnych głośników. Proces ten pomaga zautomatyzować analizę rozmów i transkrypcję dialogów w call center, rozmów medycznych i prawnych oraz spotkań.

Fonetyczna transkrypcja
W przeciwieństwie do zwykłej transkrypcji, która konwertuje dźwięk na sekwencję słów, transkrypcja fonetyczna odnotowuje wymowę słów i wizualnie przedstawia dźwięki za pomocą symboli fonetycznych. Transkrypcja fonetyczna ułatwia zauważenie różnicy w wymowie tego samego języka w kilku dialektach.

Ludzie
Dedykowane i przeszkolone zespoły:
- Ponad 30,000 współpracowników w zakresie tworzenia danych, etykietowania i kontroli jakości Q
- Uznany Zespół Zarządzania Projektami
- Doświadczony zespół rozwoju produktu
- Zespół ds. pozyskiwania i wdrażania puli talentów

Przetwarzanie
Najwyższą wydajność procesu zapewniają:
- Solidny proces 6 Sigma Stage-Gate
- Dedykowany zespół 6 czarnych pasów Sigma – Właściciele kluczowych procesów i zgodność z jakością
- Ciągłe doskonalenie i pętla sprzężenia zwrotnego

Platforma
Opatentowana platforma oferuje korzyści:
- Kompleksowa platforma internetowa
- Nienaganna jakość
- Szybsze TAT
- Bezproblemowa dostawa
Ludzie
Dedykowane i przeszkolone zespoły:
- Ponad 30,000 współpracowników w zakresie tworzenia danych, etykietowania i kontroli jakości Q
- Uznany Zespół Zarządzania Projektami
- Doświadczony zespół rozwoju produktu
- Zespół ds. pozyskiwania i wdrażania puli talentów
Przetwarzanie
Najwyższą wydajność procesu zapewniają:
- Solidny proces 6 Sigma Stage-Gate
- Dedykowany zespół 6 czarnych pasów Sigma – Właściciele kluczowych procesów i zgodność z jakością
- Ciągłe doskonalenie i pętla sprzężenia zwrotnego
Platforma
Opatentowana platforma oferuje korzyści:
- Kompleksowa platforma internetowa
- Nienaganna jakość
- Szybsze TAT
- Bezproblemowa dostawa

Adnotacja tekstowa
Usługi
Specjalizujemy się w przygotowywaniu szkoleń dotyczących danych tekstowych poprzez dodawanie adnotacji do wyczerpujących zestawów danych, korzystanie z adnotacji encji, klasyfikacji tekstu, adnotacji tonacji i innych odpowiednich narzędzi.

Adnotacja obrazu
Usługi
Jesteśmy dumni z etykietowania, segmentowanych zbiorów danych obrazu w celu trenowania modeli widzenia komputerowego. Niektóre z odpowiednich technik obejmują rozpoznawanie granic i klasyfikację obrazów.

Adnotacja wideo
Usługi
Shaip oferuje wysokiej klasy usługi etykietowania wideo do szkolenia modeli komputerowych. Celem jest uczynienie zestawów danych użytecznymi za pomocą narzędzi takich jak rozpoznawanie wzorców, wykrywanie obiektów i nie tylko.


