

Czym są modele dużych języków?
Duże modele językowe (LLM) to zaawansowane systemy sztucznej inteligencji (AI) zaprojektowane do przetwarzania, rozumienia i generowania tekstu podobnego do ludzkiego. Opierają się na technikach głębokiego uczenia i są szkolone na ogromnych zbiorach danych, zwykle zawierających miliardy słów z różnych źródeł, takich jak strony internetowe, książki i artykuły. To obszerne szkolenie umożliwia LLM uchwycenie niuansów języka, gramatyki, kontekstu, a nawet niektórych aspektów wiedzy ogólnej.
Niektóre popularne LLM, takie jak GPT-3 OpenAI, wykorzystują rodzaj sieci neuronowej zwanej transformatorem, który pozwala im obsługiwać złożone zadania językowe z niezwykłą biegłością. Modele te mogą wykonywać szeroki zakres zadań, takich jak:
- Odpowiadanie na pytania
- Tekst podsumowujący
- Tłumaczenie języków
- Generowanie treści
- Nawet angażowanie się w interaktywne rozmowy z użytkownikami
Ponieważ LLM stale ewoluują, mają ogromny potencjał w zakresie ulepszania i automatyzacji różnych aplikacji w różnych branżach, od obsługi klienta i tworzenia treści po edukację i badania. Jednak budzą one również obawy etyczne i społeczne, takie jak stronnicze zachowanie lub nadużycia, którymi należy się zająć w miarę postępu technologicznego.

Popularne przykłady dużych modeli językowych
Oto kilka wybitnych przykładów LLM szeroko stosowanych w różnych branżach:
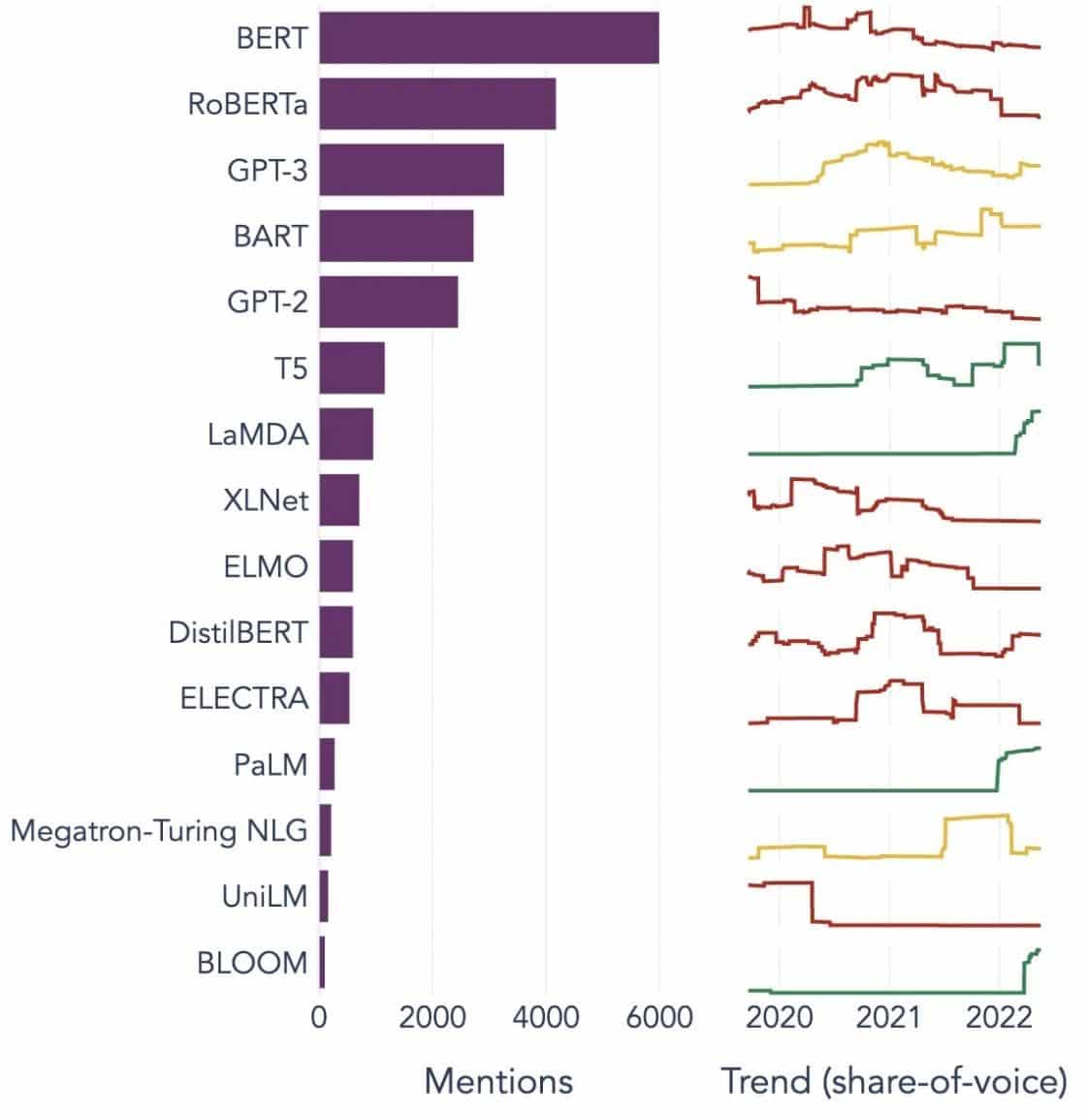
Źródło pliku: W stronę nauki o danych
W jaki sposób szkolone są modele LLM?
Szkolenie dużych modeli językowych (LLM) to nie lada wyczyn, który obejmuje kilka kluczowych kroków. Oto uproszczony opis procesu krok po kroku:
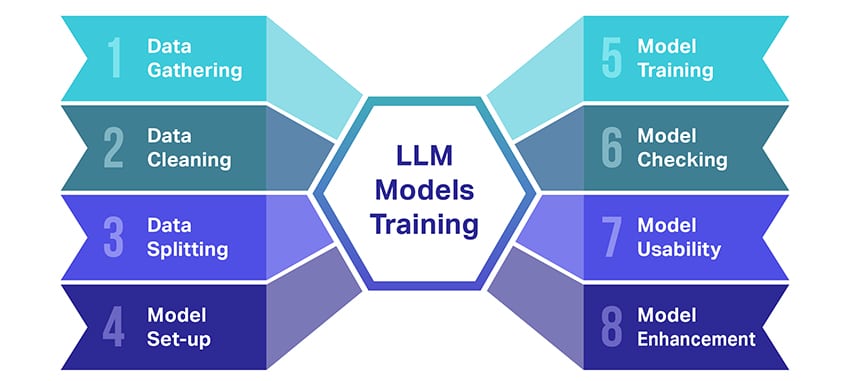
- Zbieranie danych tekstowych: Szkolenie LLM rozpoczyna się od zebrania ogromnej ilości danych tekstowych. Dane te mogą pochodzić z książek, stron internetowych, artykułów lub platform mediów społecznościowych. Celem jest uchwycenie bogatej różnorodności ludzkiego języka.
- Czyszczenie danych: Surowe dane tekstowe są następnie porządkowane w procesie zwanym przetwarzaniem wstępnym. Obejmuje to zadania takie jak usuwanie niechcianych znaków, dzielenie tekstu na mniejsze części zwane tokenami i umieszczanie wszystkiego w formacie, z którym model może pracować.
- Dzielenie danych: Następnie czyste dane są dzielone na dwa zestawy. Jeden zestaw, dane szkoleniowe, zostanie użyty do uczenia modelu. Drugi zestaw, dane walidacyjne, zostanie później użyty do przetestowania wydajności modelu.
- Konfigurowanie modelu: Następnie definiowana jest struktura LLM, znana jako architektura. Wiąże się to z wyborem rodzaju sieci neuronowej i podjęciem decyzji o różnych parametrach, takich jak liczba warstw i ukrytych jednostek w sieci.
- Szkolenie modelu: Teraz zaczyna się właściwy trening. Model LLM uczy się, patrząc na dane szkoleniowe, dokonując prognoz na podstawie tego, czego nauczył się do tej pory, a następnie dostosowując swoje parametry wewnętrzne, aby zmniejszyć różnicę między przewidywaniami a rzeczywistymi danymi.
- Sprawdzanie modelu: Uczenie się modelu LLM jest sprawdzane przy użyciu danych walidacyjnych. Pomaga to zobaczyć, jak dobrze działa model i dostosować ustawienia modelu w celu uzyskania lepszej wydajności.
- Korzystanie z modelu: Po szkoleniu i ocenie model LLM jest gotowy do użycia. Można go teraz zintegrować z aplikacjami lub systemami, w których będzie generować tekst na podstawie nowych danych wejściowych.
- Ulepszanie modelu: Wreszcie, zawsze jest miejsce na ulepszenia. Model LLM można z czasem udoskonalić, korzystając ze zaktualizowanych danych lub dostosowując ustawienia na podstawie informacji zwrotnych i rzeczywistych zastosowań.
Pamiętaj, że proces ten wymaga znacznych zasobów obliczeniowych, takich jak wydajne jednostki przetwarzające i duża pamięć masowa, a także specjalistyczną wiedzę z zakresu uczenia maszynowego. Dlatego zwykle robią to wyspecjalizowane organizacje badawcze lub firmy posiadające dostęp do niezbędnej infrastruktury i wiedzy specjalistycznej.
Czy LLM opiera się na nadzorowanym lub nienadzorowanym uczeniu się?
Duże modele językowe są zwykle szkolone przy użyciu metody zwanej uczeniem nadzorowanym. Mówiąc prościej, oznacza to, że uczą się na przykładach, które pokazują im prawidłowe odpowiedzi.
 Wyobraź sobie, że uczysz dziecko słów, pokazując mu obrazki. Pokazujesz im zdjęcie kota i mówisz „kot”, a oni uczą się kojarzyć to zdjęcie ze słowem. Tak działa nadzorowane uczenie się. Model otrzymuje dużo tekstu („obrazy”) i odpowiadające mu dane wyjściowe („słowa”) i uczy się je dopasowywać.
Wyobraź sobie, że uczysz dziecko słów, pokazując mu obrazki. Pokazujesz im zdjęcie kota i mówisz „kot”, a oni uczą się kojarzyć to zdjęcie ze słowem. Tak działa nadzorowane uczenie się. Model otrzymuje dużo tekstu („obrazy”) i odpowiadające mu dane wyjściowe („słowa”) i uczy się je dopasowywać.
Tak więc, jeśli karmisz LLM zdaniem, próbuje przewidzieć następne słowo lub frazę na podstawie tego, czego nauczył się z przykładów. W ten sposób uczy się, jak generować tekst, który ma sens i pasuje do kontekstu.
To powiedziawszy, czasami LLM również używają odrobiny uczenia się bez nadzoru. To tak, jakby pozwolić dziecku odkrywać pokój pełen różnych zabawek i uczyć się o nich samodzielnie. Model analizuje nieoznakowane dane, wzorce uczenia się i struktury bez podania „właściwych” odpowiedzi.
Uczenie nadzorowane wykorzystuje dane oznaczone danymi wejściowymi i wyjściowymi, w przeciwieństwie do uczenia nienadzorowanego, które nie wykorzystuje oznaczonych danych wyjściowych.
W skrócie, LLM są szkolone głównie przy użyciu uczenia nadzorowanego, ale mogą również wykorzystywać uczenie bez nadzoru w celu zwiększenia swoich możliwości, na przykład w zakresie analizy eksploracyjnej i redukcji wymiarowości.
Jaka jest ilość danych (w GB) niezbędna do nauczenia dużego modelu językowego?
Świat możliwości rozpoznawania danych głosowych i aplikacji głosowych jest ogromny i są one wykorzystywane w wielu branżach do wielu zastosowań.
Szkolenie dużego modelu językowego nie jest procesem uniwersalnym, zwłaszcza jeśli chodzi o potrzebne dane. To zależy od wielu rzeczy:
- Projekt modelu.
- Jakie zadanie musi wykonać?
- Typ używanych danych.
- Jak dobrze chcesz, żeby działał?
To powiedziawszy, szkolenie LLM zwykle wymaga ogromnej ilości danych tekstowych. Ale o jakiej masie mówimy? Cóż, pomyśl o czymś więcej niż gigabajty (GB). Zwykle patrzymy na terabajty (TB), a nawet petabajty (PB) danych.
Weźmy pod uwagę GPT-3, jeden z największych LLM na rynku. Jest szkolony na 570 GB danych tekstowych. Mniejsze LLM mogą potrzebować mniej – może 10-20 GB lub nawet 1 GB gigabajtów – ale to wciąż dużo.

Ale nie chodzi tylko o rozmiar danych. Jakość też ma znaczenie. Dane muszą być czyste i zróżnicowane, aby model mógł efektywnie się uczyć. Nie możesz też zapomnieć o innych kluczowych elementach układanki, takich jak potrzebna moc obliczeniowa, algorytmy używane do trenowania i konfiguracja sprzętu. Wszystkie te czynniki odgrywają dużą rolę w szkoleniu LLM.
Powstanie dużych modeli językowych: dlaczego mają znaczenie
LLM nie są już tylko koncepcją ani eksperymentem. Coraz częściej odgrywają one kluczową rolę w naszym cyfrowym krajobrazie. Ale dlaczego tak się dzieje? Dlaczego te LLM są tak ważne? Przyjrzyjmy się kilku kluczowym czynnikom.
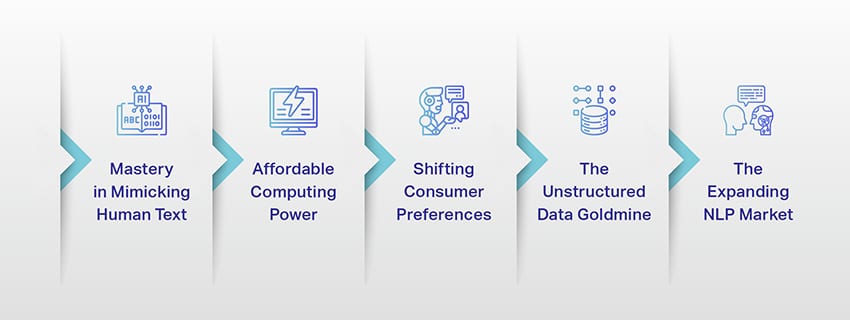
Mistrzostwo w naśladowaniu ludzkiego tekstu
LLM zmieniły sposób, w jaki radzimy sobie z zadaniami językowymi. Zbudowane przy użyciu solidnych algorytmów uczenia maszynowego modele te są wyposażone w możliwość zrozumienia niuansów ludzkiego języka, w tym kontekstu, emocji, a nawet do pewnego stopnia sarkazmu. Ta zdolność do naśladowania ludzkiego języka nie jest zwykłą nowością, ma ona istotne implikacje.
Zaawansowane możliwości generowania tekstu LLM mogą ulepszyć wszystko, od tworzenia treści po interakcje z obsługą klienta.
Wyobraź sobie, że możesz zadać cyfrowemu asystentowi złożone pytanie i uzyskać odpowiedź, która nie tylko ma sens, ale jest również spójna, trafna i przekazana w konwersacyjnym tonie. To właśnie umożliwiają LLM. Napędzają bardziej intuicyjną i angażującą interakcję człowiek-maszyna, wzbogacając doświadczenia użytkowników i demokratyzując dostęp do informacji.
Przystępna moc obliczeniowa
Powstanie LLM nie byłoby możliwe bez równoległego rozwoju w dziedzinie informatyki. Mówiąc dokładniej, demokratyzacja zasobów obliczeniowych odegrała znaczącą rolę w ewolucji i przyjęciu LLM.
Platformy oparte na chmurze oferują bezprecedensowy dostęp do wysokowydajnych zasobów obliczeniowych. W ten sposób nawet małe organizacje i niezależni badacze mogą trenować zaawansowane modele uczenia maszynowego.
Co więcej, ulepszenia jednostek przetwarzających (takich jak GPU i TPU) w połączeniu z rozwojem przetwarzania rozproszonego umożliwiły trenowanie modeli z miliardami parametrów. Ta zwiększona dostępność mocy obliczeniowej umożliwia rozwój i sukces LLM, prowadząc do większej liczby innowacji i aplikacji w tej dziedzinie.
Zmiana preferencji konsumentów
Dzisiejsi konsumenci nie chcą tylko odpowiedzi; chcą angażujących i relatywnych interakcji. Ponieważ coraz więcej osób dorasta, korzystając z technologii cyfrowej, oczywiste jest, że rośnie zapotrzebowanie na technologię, która wydaje się bardziej naturalna i przypomina człowieka. LLM oferują niezrównaną możliwość spełnienia tych oczekiwań. Generując tekst podobny do ludzkiego, modele te mogą tworzyć wciągające i dynamiczne doświadczenia cyfrowe, które mogą zwiększyć zadowolenie i lojalność użytkowników. Niezależnie od tego, czy są to chatboty AI zapewniające obsługę klienta, czy asystenci głosowi dostarczający aktualizacje wiadomości, LLM wprowadzają erę sztucznej inteligencji, która lepiej nas rozumie.
Nieustrukturyzowana kopalnia danych
Nieustrukturyzowane dane, takie jak e-maile, posty w mediach społecznościowych i recenzje klientów, to skarbnica wiedzy. Szacuje się, że to koniec 80% danych korporacyjnych jest nieustrukturyzowanych i rośnie w tempie ok 55% na rok. Dane te są kopalnią złota dla firm, jeśli zostaną odpowiednio wykorzystane.
W grę wchodzą tutaj LLM, z ich zdolnością do przetwarzania i nadawania sensu takim danym na dużą skalę. Mogą wykonywać takie zadania, jak analiza tonacji, klasyfikacja tekstu, ekstrakcja informacji i inne, dostarczając w ten sposób cennych informacji.
Niezależnie od tego, czy chodzi o identyfikowanie trendów na podstawie postów w mediach społecznościowych, czy mierzenie nastrojów klientów na podstawie recenzji, LLM pomagają firmom poruszać się po dużej ilości nieustrukturyzowanych danych i podejmować decyzje oparte na danych.
Rozwijający się rynek NLP
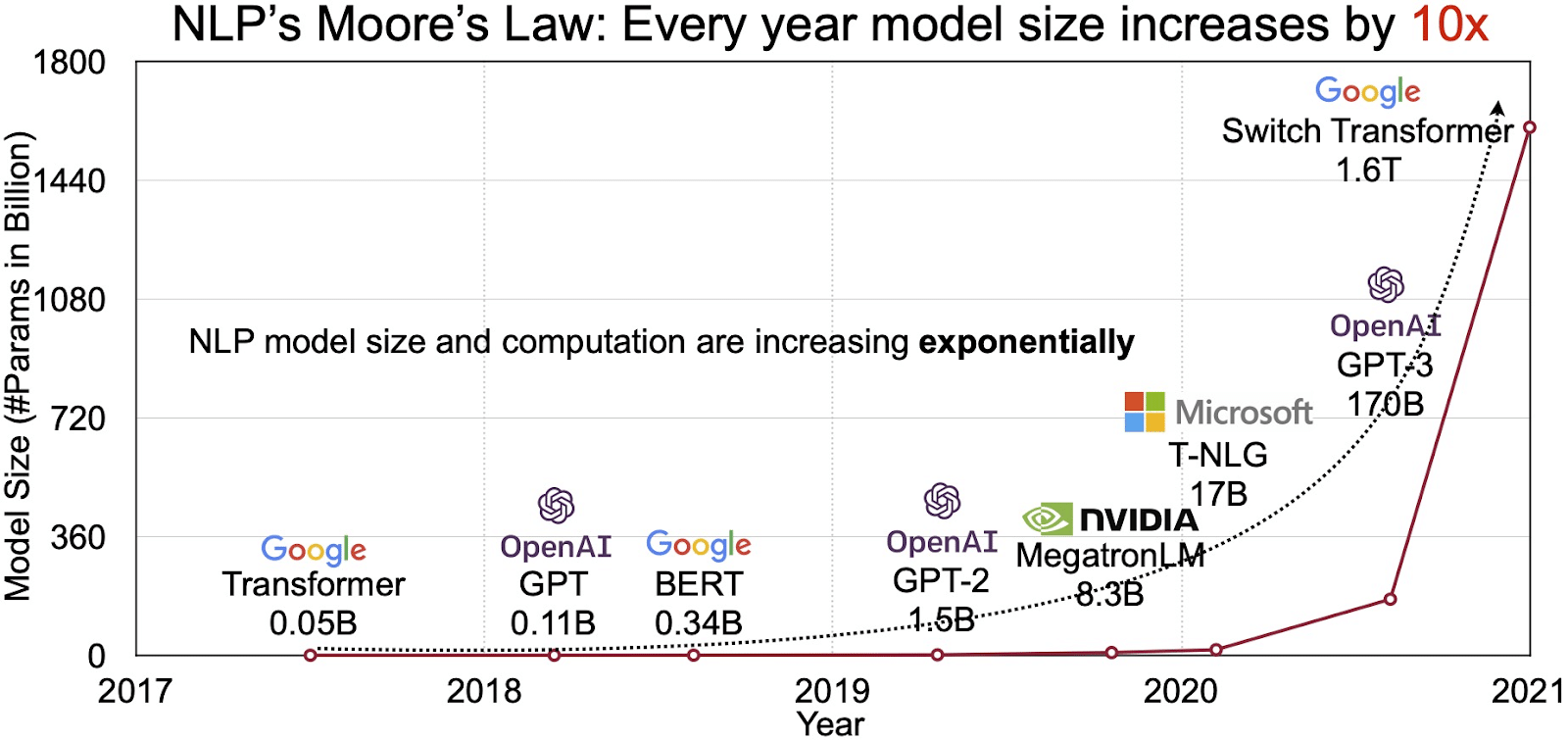
Potencjał LLM znajduje odzwierciedlenie w szybko rozwijającym się rynku przetwarzania języka naturalnego (NLP). Analitycy przewidują, że rynek NLP będzie się rozwijał 11 miliardów dolarów w 2020 roku do ponad 35 miliardów dolarów do 2026 roku. Ale nie tylko wielkość rynku się rozwija. Same modele również rosną, zarówno pod względem rozmiaru fizycznego, jak i liczby parametrów, które obsługują. Ewolucja LLM na przestrzeni lat, jak widać na poniższym rysunku (źródło obrazu: link), podkreśla ich rosnącą złożoność i pojemność.
Popularne przypadki użycia dużych modeli językowych
Oto niektóre z najlepszych i najbardziej rozpowszechnionych przypadków użycia LLM:
- Generowanie tekstu w języku naturalnym: Duże modele językowe (LLM) łączą moc sztucznej inteligencji i lingwistyki komputerowej w celu autonomicznego tworzenia tekstów w języku naturalnym. Mogą zaspokoić różnorodne potrzeby użytkowników, takie jak pisanie artykułów, tworzenie piosenek lub angażowanie się w rozmowy z użytkownikami.
- Tłumaczenie przez maszyny: LLM można skutecznie wykorzystać do tłumaczenia tekstu między dowolną parą języków. Modele te wykorzystują algorytmy głębokiego uczenia się, takie jak rekurencyjne sieci neuronowe, do zrozumienia struktury językowej zarówno języka źródłowego, jak i docelowego, ułatwiając w ten sposób tłumaczenie tekstu źródłowego na żądany język.
- Tworzenie oryginalnej zawartości: LLM otworzyły możliwości dla maszyn do generowania spójnej i logicznej treści. Ta zawartość może być używana do tworzenia postów na blogach, artykułów i innych typów treści. Modele wykorzystują swoje dogłębne doświadczenie w zakresie głębokiego uczenia się, aby sformatować i uporządkować treści w nowatorski i przyjazny dla użytkownika sposób.
- Analiza nastrojów: Intrygującym zastosowaniem dużych modeli językowych jest analiza nastrojów. W tym przypadku model jest szkolony w rozpoznawaniu i kategoryzowaniu stanów emocjonalnych i uczuć obecnych w tekście z adnotacjami. Oprogramowanie może identyfikować emocje, takie jak pozytywność, negatywność, neutralność i inne skomplikowane uczucia. Może to zapewnić cenny wgląd w opinie klientów i opinie na temat różnych produktów i usług.
- Rozumienie, streszczanie i klasyfikowanie tekstu: LLM tworzą realną strukturę dla oprogramowania AI do interpretacji tekstu i jego kontekstu. Instruując model, aby rozumiał i analizował ogromne ilości danych, LLM umożliwiają modelom AI zrozumienie, podsumowanie, a nawet kategoryzację tekstu w różnych formach i wzorach.
- Odpowiadanie na pytania: Duże modele językowe wyposażają systemy odpowiadania na pytania (QA) w możliwość dokładnego postrzegania i odpowiadania na zapytania użytkownika w języku naturalnym. Popularnymi przykładami tego przypadku użycia są ChatGPT i BERT, które badają kontekst zapytania i przeszukują ogromny zbiór tekstów, aby dostarczyć odpowiednie odpowiedzi na pytania użytkowników.

Oznaczanie części mowy (POS).
Słowa w zdaniach są oznaczane ich funkcją gramatyczną, taką jak czasowniki, rzeczowniki, przymiotniki itp. Ten proces pomaga modelowi w zrozumieniu gramatyki i powiązań między słowami.

Rozpoznawanie nazwanych jednostek (NER)
Nazwane jednostki, takie jak organizacje, lokalizacje i osoby w zdaniu, są zaznaczone. To ćwiczenie pomaga modelowi w interpretacji semantycznych znaczeń słów i wyrażeń oraz dostarcza bardziej precyzyjnych odpowiedzi.

Analiza sentymentów
Dane tekstowe są przypisywane do etykiet tonacji, takich jak pozytywne, neutralne lub negatywne, pomagając modelowi uchwycić emocjonalny podtekst zdań. Jest to szczególnie przydatne w odpowiadaniu na zapytania dotyczące emocji i opinii.
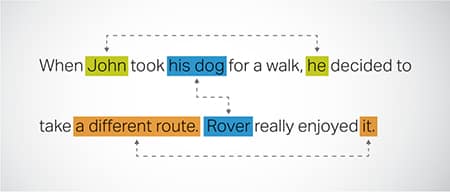
Rozdzielczość odniesienia
Identyfikowanie i rozwiązywanie przypadków, w których ten sam podmiot jest przywoływany w różnych częściach tekstu. Ten krok pomaga modelowi zrozumieć kontekst zdania, prowadząc w ten sposób do spójnych odpowiedzi.
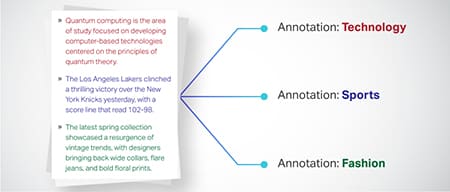
Klasyfikacja tekstu
Dane tekstowe są podzielone na predefiniowane grupy, takie jak recenzje produktów lub artykuły z wiadomościami. Pomaga to modelowi w rozpoznaniu gatunku lub tematu tekstu, generując bardziej trafne odpowiedzi.
Oferta Shaipa
Szaip oferuje szeroki zakres usług pomagających organizacjom zarządzać danymi, analizować je i optymalnie wykorzystywać.
Pobieranie danych z sieci
Jedną z kluczowych usług oferowanych przez Shaip jest zbieranie danych. Obejmuje to wyodrębnianie danych z adresów URL specyficznych dla domeny. Wykorzystując zautomatyzowane narzędzia i techniki, Shaip może szybko i skutecznie zbierać duże ilości danych z różnych stron internetowych, instrukcji produktów, dokumentacji technicznej, forów internetowych, recenzji online, danych obsługi klienta, branżowych dokumentów regulacyjnych itp. Ten proces może być nieoceniony dla firm, gdy gromadzenie odpowiednich i konkretnych danych z wielu źródeł.

Tłumaczenie maszynowe
Twórz modele przy użyciu obszernych wielojęzycznych zestawów danych w połączeniu z odpowiednimi transkrypcjami do tłumaczenia tekstu na różne języki. Proces ten pomaga usuwać przeszkody językowe i promuje dostępność informacji.
Ekstrakcja i tworzenie taksonomii
Shaip może pomóc w wyodrębnianiu i tworzeniu taksonomii. Obejmuje to klasyfikowanie i kategoryzowanie danych w ustrukturyzowanym formacie, który odzwierciedla relacje między różnymi punktami danych. Może to być szczególnie przydatne dla firm w organizowaniu danych, czyniąc je bardziej dostępnymi i łatwiejszymi do analizy. Na przykład w branży e-commerce dane produktów można kategoryzować na podstawie typu produktu, marki, ceny itp., co ułatwia klientom poruszanie się po katalogu produktów.
Zbieranie danych
Nasze usługi gromadzenia danych dostarczają krytycznych danych rzeczywistych lub syntetycznych niezbędnych do szkolenia generatywnych algorytmów sztucznej inteligencji oraz poprawy dokładności i skuteczności modeli. Dane są bezstronne, pozyskiwane w sposób etyczny i odpowiedzialny, przy jednoczesnym zachowaniu prywatności i bezpieczeństwa danych.

Pytania i odpowiedzi
Odpowiadanie na pytania (QA) to poddziedzina przetwarzania języka naturalnego skoncentrowana na automatycznym odpowiadaniu na pytania w ludzkim języku. Systemy kontroli jakości są szkolone na obszernym tekście i kodzie, co umożliwia im obsługę różnego rodzaju pytań, w tym pytań dotyczących faktów, definicji i opinii. Znajomość domeny ma kluczowe znaczenie dla opracowywania modeli zapewniania jakości dostosowanych do konkretnych dziedzin, takich jak obsługa klienta, opieka zdrowotna czy łańcuch dostaw. Jednak generatywne podejście do zapewniania jakości umożliwia modelom generowanie tekstu bez znajomości domeny, opierając się wyłącznie na kontekście.
Nasz zespół specjalistów może skrupulatnie przestudiować obszerne dokumenty lub instrukcje w celu wygenerowania par pytanie-odpowiedź, ułatwiając tworzenie generatywnej sztucznej inteligencji dla firm. Takie podejście może skutecznie odpowiadać na zapytania użytkowników, wydobywając istotne informacje z obszernego korpusu. Nasi certyfikowani eksperci zapewniają tworzenie najwyższej jakości par pytań i odpowiedzi obejmujących różnorodne tematy i domeny.

Podsumowanie tekstu
Nasi specjaliści są w stanie wyodrębnić obszerne rozmowy lub długie dialogi, dostarczając zwięzłe i wnikliwe podsumowania z obszernych danych tekstowych.

Generowanie tekstu
Trenuj modele przy użyciu szerokiego zestawu danych tekstu w różnych stylach, takich jak artykuły z wiadomościami, beletrystyka i poezja. Modele te mogą następnie generować różne rodzaje treści, w tym wiadomości, wpisy na blogach lub posty w mediach społecznościowych, oferując opłacalne i oszczędzające czas rozwiązanie do tworzenia treści.
Rozpoznawanie mowy
Opracuj modele zdolne do zrozumienia języka mówionego dla różnych zastosowań. Obejmuje to asystentów aktywowanych głosem, oprogramowanie do dyktowania i narzędzia do tłumaczenia w czasie rzeczywistym. Proces obejmuje wykorzystanie kompleksowego zestawu danych składającego się z nagrań dźwiękowych języka mówionego w połączeniu z odpowiadającymi im transkrypcjami.

Rekomendacje produktu
Twórz modele, korzystając z obszernych zbiorów danych dotyczących historii zakupów klientów, w tym etykiet wskazujących produkty, które klienci są skłonni kupować. Celem jest dostarczanie klientom precyzyjnych sugestii, a tym samym zwiększanie sprzedaży i zwiększanie zadowolenia klientów.
Podpisy obrazów
Zrewolucjonizuj proces interpretacji obrazu dzięki naszej najnowocześniejszej, opartej na sztucznej inteligencji usłudze tworzenia podpisów pod obrazami. Tchniemy witalność w zdjęcia, tworząc dokładne i kontekstowo zrozumiałe opisy. To otwiera drogę do innowacyjnych możliwości zaangażowania i interakcji z treściami wizualnymi dla odbiorców.

Szkolenia usług zamiany tekstu na mowę
Zapewniamy obszerny zestaw danych składający się z nagrań dźwiękowych ludzkiej mowy, idealny do szkolenia modeli AI. Modele te są w stanie generować naturalne i wciągające głosy dla twoich aplikacji, zapewniając w ten sposób charakterystyczne i wciągające wrażenia dźwiękowe dla twoich użytkowników.



