




Wzmocnienie opieki zdrowotnej dzięki generatywnej sztucznej inteligencji: rewolucyjna diagnoza i leczenie
W ostatnich latach sztuczna inteligencja (AI) poczyniła znaczne postępy w różnych branżach, a opieka zdrowotna nie jest wyjątkiem. Generatywna sztuczna inteligencja, podzbiór skupiony na sztucznej inteligencji
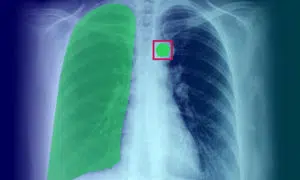
Adnotacja obrazu medycznego: definicja, zastosowanie, przypadki użycia i typy
Adnotacja obrazu medycznego odgrywa kluczową rolę w dostarczaniu algorytmom uczenia maszynowego i modelom AI niezbędnych danych szkoleniowych. Proces ten jest niezbędny dla

Etyka i uprzedzenia: radzenie sobie z wyzwaniami związanymi ze współpracą człowieka i sztucznej inteligencji w ocenie modelu
Chcąc wykorzystać transformacyjną moc sztucznej inteligencji (AI), społeczność technologiczna stoi przed zasadniczym wyzwaniem: zapewnienie integralności etycznej i minimalizacja uprzedzeń

Ludzki dotyk: zwiększanie kreatywności sztucznej inteligencji dzięki subiektywnej ocenie
W szybko rozwijającym się świecie sztucznej inteligencji (AI) poszukiwanie kreatywności nie jest już wyłącznie domeną człowieka. Dzisiejsze technologie AI załamują się

Maksymalizacja trafności wyszukiwania dzięki etykietowaniu danych: wskazówki i najlepsze praktyki
Dzisiejsi użytkownicy są zanurzeni w ogromnych ilościach informacji, co sprawia, że znalezienie potrzebnych informacji jest skomplikowane. Trafność wyszukiwania mierzy dokładność informacji

Wypełnianie luki: integrowanie ludzkiej intuicji w ocenie modelu AI
Wprowadzenie W epoce, w której sztuczna inteligencja (AI) kształtuje każdy aspekt naszego życia, włączenie ludzkiej intuicji do oceny modelu sztucznej inteligencji wydaje się być

Najlepsze zbiory danych typu open source dotyczące opieki zdrowotnej na potrzeby projektów uczenia maszynowego
Globalny system opieki zdrowotnej codziennie generuje ogromne ilości danych medycznych, które można wykorzystać w zastosowaniach uczenia maszynowego.

Nawigacja po prywatności danych w sztucznej inteligencji: strategie zgodności i innowacji
Wprowadzenie W szybko rozwijającym się środowisku sztucznej inteligencji (AI) firmy takie jak OpenAI stoją przed poważnymi wyzwaniami związanymi z równoważeniem niezaspokojonego zapotrzebowania na dane z rygorystycznymi
Przyszłość danych dzięki inteligentnemu rozpoznawaniu znaków (ICR)
Odręczne notatki mają szczególny urok nawet w naszym cyfrowym świecie. Inteligentne rozpoznawanie znaków (ICR) pomaga pokonać przepaść analogową i cyfrową, konwertując tekst pisany odręcznie

Wpływ NLP na diagnostykę opieki zdrowotnej
Przetwarzanie języka naturalnego (NLP) zmienia sposób, w jaki wchodzimy w interakcję z technologią. Przetwarza ludzki język, aby odblokować ogromny potencjał informacyjny. Technologia ma ten sam potencjał

Wybór odpowiedniego zbioru danych do rozpoznawania mowy dla Twojego modelu AI
Wyobraź sobie interakcję z Siri lub Alexą. Ich umiejętność rozumienia naszej mowy jest fascynująca. Możliwość ta wynika ze zbiorów danych wykorzystywanych w ich szkoleniu. Te

Zbiory danych dotyczące opieki zdrowotnej: dobrodziejstwo dla sztucznej inteligencji w służbie zdrowia
Sztuczna inteligencja, termin występujący niegdyś głównie w science fiction, jest obecnie rzeczywistością napędzającą rozwój różnych gałęzi przemysłu. Następny ruch Doradztwo strategiczne

Uczenie się ze wzmocnieniem za pomocą informacji zwrotnej od człowieka: definicja i kroki
Uczenie się przez wzmacnianie (RL) to rodzaj uczenia maszynowego. W tym podejściu algorytmy uczą się podejmować decyzje metodą prób i błędów, podobnie jak robią to ludzie.

Przyczyny halucynacji AI (i techniki ich ograniczania)
Halucynacje AI odnoszą się do przypadków, w których modele AI, w szczególności modele dużych języków (LLM), generują informacje, które wydają się prawdziwe, ale są nieprawidłowe lub niezwiązane z rzeczywistością.

Co to jest walidacja kliniczna? Twój przewodnik po najlepszych praktykach i procesach
Pomyśl o scenariuszu, w którym opracowywane jest nowe narzędzie diagnostyczne. Lekarze są podekscytowani jego potencjałem. Jednak przed włączeniem tego do rutynowej opieki, oni

Znaczenie etycznej sztucznej inteligencji / uczciwej sztucznej inteligencji i rodzaje uprzedzeń, których należy unikać
W rozwijającej się dziedzinie sztucznej inteligencji (AI) skupienie się na względach etycznych i uczciwości to coś więcej niż imperatyw moralny – to fundamentalna konieczność

Podsumowanie dokumentacji medycznej AI: definicja, wyzwania i najlepsze praktyki
Rozwój dokumentacji medycznej w branży opieki zdrowotnej stał się zarówno wyzwaniem, jak i szansą. Wyobraź sobie świat, w którym każdy szczegół w

Abstrakcja danych klinicznych: definicja, proces i nie tylko
Szpitale i kliniki każdego roku przyjmują tysiące pacjentów. Do tego potrzeba ogromnej liczby oddanych lekarzy i pielęgniarek. Pracują niestrudzenie, aby zapewnić opiekę

Dane syntetyczne w opiece zdrowotnej: definicja, korzyści i wyzwania
Wyobraźmy sobie scenariusz, w którym naukowcy opracowują nowy lek. Do testów potrzebują obszernych danych pacjentów, istnieją jednak poważne obawy dotyczące prywatności i

Ustalenie eksperta HIPAA dotyczące deidentyfikacji
Ustawa o przenośności i odpowiedzialności w ubezpieczeniach zdrowotnych (HIPAA) ustanawia standardy ochrony danych pacjentów w opiece zdrowotnej. Kluczowym aspektem tego jest deidentyfikacja Protected

Pionierskie badania onkologiczne z wykorzystaniem NLP: przełom Shaip
Pobierz studium przypadku W walce z rakiem dane są równie istotne jak determinacja. W Shaip jesteśmy dumni, że umożliwiliśmy znaczący skok
Moc przetwarzania języka naturalnego (NLP) w radiologii: poprawa diagnozy i wydajności
Radiologia odgrywa kluczową rolę w opiece zdrowotnej. Wykorzystuje techniki obrazowania, takie jak tomografia komputerowa, zdjęcia rentgenowskie i rezonans magnetyczny, do diagnozowania i leczenia różnych schorzeń. Język naturalny

Rola przetwarzania języka naturalnego (NLP) w onkologii
Rak stanowi poważne wyzwanie zdrowotne na całym świecie. Dzieje się tak, gdy komórki rosną i rozprzestrzeniają się w niekontrolowany sposób. To druga najczęstsza przyczyna zgonów

Wszystko, co musisz wiedzieć o uczeniu się przez wzmacnianie na podstawie informacji zwrotnej od ludzi
W 2023 r. nastąpił ogromny wzrost wykorzystania narzędzi AI, takich jak ChatGPT. Ten wzrost zapoczątkował ożywioną debatę, a ludzie dyskutują o korzyściach płynących ze sztucznej inteligencji,

Siła sztucznej inteligencji w branży motoryzacyjnej
Jeśli chodzi o integrację sztucznej inteligencji z samochodami, świat stoi na niezwykłym rozdrożu. Wyobraź sobie, że jedziesz ruchliwą drogą ze sztuczną inteligencją i zarządzasz swoimi

Korzyści z zamiany tekstu na mowę w różnych branżach
Technologia zamiany tekstu na mowę (TTS) to innowacyjne rozwiązanie, które przekształca tekst pisany na słowa mówione. Zmieniło zasady gry w kilku branżach i zrewolucjonizowało

Od A do Z adnotacji danych
Przewodnik dla początkujących po adnotacjach danych: wskazówki i najlepsze praktyki The Ultimate Buyers Guide 2024 Spis indeksu Wprowadzenie Czym jest uczenie maszynowe? Co jest

Przewodnik po deidentyfikacji danych: wszystko, co powinien wiedzieć początkujący (w 2024 r.)
W dobie transformacji cyfrowej organizacje opieki zdrowotnej szybko przenoszą swoją działalność na platformy cyfrowe. Zapewnia to wydajność i usprawnienie procesów, ale także

Generatywna sztuczna inteligencja w opiece zdrowotnej: zastosowania, zalety, wyzwania i przyszłe trendy
Opieka zdrowotna zawsze była dziedziną, w której ceniono innowacje i które miały kluczowe znaczenie dla ratowania życia. Pomimo postępu technologicznego branża opieki zdrowotnej nadal stoi przed utrzymującymi się wyzwaniami.

Różnica między odpowiedzialną sztuczną inteligencją a etyczną sztuczną inteligencją
Oczekuje się, że szybko rozwijający się światowy rynek sztucznej inteligencji osiągnie w 1847 r. wartość 2030 miliardów dolarów. Ponieważ sztuczna inteligencja zajmuje centralne miejsce w naszym życiu, wiedząc, jakiego rodzaju



















Wzmocnienie opieki zdrowotnej dzięki generatywnej sztucznej inteligencji: rewolucyjna diagnoza i leczenie
W ostatnich latach sztuczna inteligencja (AI) poczyniła znaczne postępy w różnych branżach, a opieka zdrowotna nie jest wyjątkiem. Generatywna sztuczna inteligencja, podzbiór skupiony na sztucznej inteligencji
Adnotacja obrazu medycznego: definicja, zastosowanie, przypadki użycia i typy
Adnotacja obrazu medycznego odgrywa kluczową rolę w dostarczaniu algorytmom uczenia maszynowego i modelom AI niezbędnych danych szkoleniowych. Proces ten jest niezbędny dla
Etyka i uprzedzenia: radzenie sobie z wyzwaniami związanymi ze współpracą człowieka i sztucznej inteligencji w ocenie modelu
Chcąc wykorzystać transformacyjną moc sztucznej inteligencji (AI), społeczność technologiczna stoi przed zasadniczym wyzwaniem: zapewnienie integralności etycznej i minimalizacja uprzedzeń
Ludzki dotyk: zwiększanie kreatywności sztucznej inteligencji dzięki subiektywnej ocenie
W szybko rozwijającym się świecie sztucznej inteligencji (AI) poszukiwanie kreatywności nie jest już wyłącznie domeną człowieka. Dzisiejsze technologie AI załamują się
Maksymalizacja trafności wyszukiwania dzięki etykietowaniu danych: wskazówki i najlepsze praktyki
Dzisiejsi użytkownicy są zanurzeni w ogromnych ilościach informacji, co sprawia, że znalezienie potrzebnych informacji jest skomplikowane. Trafność wyszukiwania mierzy dokładność informacji
Wypełnianie luki: integrowanie ludzkiej intuicji w ocenie modelu AI
Wprowadzenie W epoce, w której sztuczna inteligencja (AI) kształtuje każdy aspekt naszego życia, włączenie ludzkiej intuicji do oceny modelu sztucznej inteligencji wydaje się być
Najlepsze zbiory danych typu open source dotyczące opieki zdrowotnej na potrzeby projektów uczenia maszynowego
Globalny system opieki zdrowotnej codziennie generuje ogromne ilości danych medycznych, które można wykorzystać w zastosowaniach uczenia maszynowego.
Nawigacja po prywatności danych w sztucznej inteligencji: strategie zgodności i innowacji
Wprowadzenie W szybko rozwijającym się środowisku sztucznej inteligencji (AI) firmy takie jak OpenAI stoją przed poważnymi wyzwaniami związanymi z równoważeniem niezaspokojonego zapotrzebowania na dane z rygorystycznymi
Przyszłość danych dzięki inteligentnemu rozpoznawaniu znaków (ICR)
Odręczne notatki mają szczególny urok nawet w naszym cyfrowym świecie. Inteligentne rozpoznawanie znaków (ICR) pomaga pokonać przepaść analogową i cyfrową, konwertując tekst pisany odręcznie
Wpływ NLP na diagnostykę opieki zdrowotnej
Przetwarzanie języka naturalnego (NLP) zmienia sposób, w jaki wchodzimy w interakcję z technologią. Przetwarza ludzki język, aby odblokować ogromny potencjał informacyjny. Technologia ma ten sam potencjał
Wybór odpowiedniego zbioru danych do rozpoznawania mowy dla Twojego modelu AI
Wyobraź sobie interakcję z Siri lub Alexą. Ich umiejętność rozumienia naszej mowy jest fascynująca. Możliwość ta wynika ze zbiorów danych wykorzystywanych w ich szkoleniu. Te
Zbiory danych dotyczące opieki zdrowotnej: dobrodziejstwo dla sztucznej inteligencji w służbie zdrowia
Sztuczna inteligencja, termin występujący niegdyś głównie w science fiction, jest obecnie rzeczywistością napędzającą rozwój różnych gałęzi przemysłu. Następny ruch Doradztwo strategiczne
Uczenie się ze wzmocnieniem za pomocą informacji zwrotnej od człowieka: definicja i kroki
Uczenie się przez wzmacnianie (RL) to rodzaj uczenia maszynowego. W tym podejściu algorytmy uczą się podejmować decyzje metodą prób i błędów, podobnie jak robią to ludzie.
Przyczyny halucynacji AI (i techniki ich ograniczania)
Halucynacje AI odnoszą się do przypadków, w których modele AI, w szczególności modele dużych języków (LLM), generują informacje, które wydają się prawdziwe, ale są nieprawidłowe lub niezwiązane z rzeczywistością.
Co to jest walidacja kliniczna? Twój przewodnik po najlepszych praktykach i procesach
Pomyśl o scenariuszu, w którym opracowywane jest nowe narzędzie diagnostyczne. Lekarze są podekscytowani jego potencjałem. Jednak przed włączeniem tego do rutynowej opieki, oni
Znaczenie etycznej sztucznej inteligencji / uczciwej sztucznej inteligencji i rodzaje uprzedzeń, których należy unikać
W rozwijającej się dziedzinie sztucznej inteligencji (AI) skupienie się na względach etycznych i uczciwości to coś więcej niż imperatyw moralny – to fundamentalna konieczność
Podsumowanie dokumentacji medycznej AI: definicja, wyzwania i najlepsze praktyki
Rozwój dokumentacji medycznej w branży opieki zdrowotnej stał się zarówno wyzwaniem, jak i szansą. Wyobraź sobie świat, w którym każdy szczegół w
Abstrakcja danych klinicznych: definicja, proces i nie tylko
Szpitale i kliniki każdego roku przyjmują tysiące pacjentów. Do tego potrzeba ogromnej liczby oddanych lekarzy i pielęgniarek. Pracują niestrudzenie, aby zapewnić opiekę
Dane syntetyczne w opiece zdrowotnej: definicja, korzyści i wyzwania
Wyobraźmy sobie scenariusz, w którym naukowcy opracowują nowy lek. Do testów potrzebują obszernych danych pacjentów, istnieją jednak poważne obawy dotyczące prywatności i
Ustalenie eksperta HIPAA dotyczące deidentyfikacji
Ustawa o przenośności i odpowiedzialności w ubezpieczeniach zdrowotnych (HIPAA) ustanawia standardy ochrony danych pacjentów w opiece zdrowotnej. Kluczowym aspektem tego jest deidentyfikacja Protected
Pionierskie badania onkologiczne z wykorzystaniem NLP: przełom Shaip
Pobierz studium przypadku W walce z rakiem dane są równie istotne jak determinacja. W Shaip jesteśmy dumni, że umożliwiliśmy znaczący skok
Moc przetwarzania języka naturalnego (NLP) w radiologii: poprawa diagnozy i wydajności
Radiologia odgrywa kluczową rolę w opiece zdrowotnej. Wykorzystuje techniki obrazowania, takie jak tomografia komputerowa, zdjęcia rentgenowskie i rezonans magnetyczny, do diagnozowania i leczenia różnych schorzeń. Język naturalny
Rola przetwarzania języka naturalnego (NLP) w onkologii
Rak stanowi poważne wyzwanie zdrowotne na całym świecie. Dzieje się tak, gdy komórki rosną i rozprzestrzeniają się w niekontrolowany sposób. To druga najczęstsza przyczyna zgonów
Wszystko, co musisz wiedzieć o uczeniu się przez wzmacnianie na podstawie informacji zwrotnej od ludzi
W 2023 r. nastąpił ogromny wzrost wykorzystania narzędzi AI, takich jak ChatGPT. Ten wzrost zapoczątkował ożywioną debatę, a ludzie dyskutują o korzyściach płynących ze sztucznej inteligencji,
Siła sztucznej inteligencji w branży motoryzacyjnej
Jeśli chodzi o integrację sztucznej inteligencji z samochodami, świat stoi na niezwykłym rozdrożu. Wyobraź sobie, że jedziesz ruchliwą drogą ze sztuczną inteligencją i zarządzasz swoimi
Korzyści z zamiany tekstu na mowę w różnych branżach
Technologia zamiany tekstu na mowę (TTS) to innowacyjne rozwiązanie, które przekształca tekst pisany na słowa mówione. Zmieniło zasady gry w kilku branżach i zrewolucjonizowało
Od A do Z adnotacji danych
Przewodnik dla początkujących po adnotacjach danych: wskazówki i najlepsze praktyki The Ultimate Buyers Guide 2024 Spis indeksu Wprowadzenie Czym jest uczenie maszynowe? Co jest
Przewodnik po deidentyfikacji danych: wszystko, co powinien wiedzieć początkujący (w 2024 r.)
W dobie transformacji cyfrowej organizacje opieki zdrowotnej szybko przenoszą swoją działalność na platformy cyfrowe. Zapewnia to wydajność i usprawnienie procesów, ale także
Generatywna sztuczna inteligencja w opiece zdrowotnej: zastosowania, zalety, wyzwania i przyszłe trendy
Opieka zdrowotna zawsze była dziedziną, w której ceniono innowacje i które miały kluczowe znaczenie dla ratowania życia. Pomimo postępu technologicznego branża opieki zdrowotnej nadal stoi przed utrzymującymi się wyzwaniami.
Różnica między odpowiedzialną sztuczną inteligencją a etyczną sztuczną inteligencją
Oczekuje się, że szybko rozwijający się światowy rynek sztucznej inteligencji osiągnie w 1847 r. wartość 2030 miliardów dolarów. Ponieważ sztuczna inteligencja zajmuje centralne miejsce w naszym życiu, wiedząc, jakiego rodzaju

Co to jest NLP? Jak to działa, korzyści, wyzwania, przykłady
Pobierz infografikę Co to jest NLP? Przetwarzanie języka naturalnego (NLP) to poddziedzina sztucznej inteligencji (AI). Umożliwia robotom analizowanie i rozumienie ludzkiego języka,

OCR – definicja, korzyści, wyzwania i przypadki użycia [Infografika]
OCR to technologia, która umożliwia maszynom odczytywanie drukowanego tekstu i obrazów. Jest często używany w aplikacjach biznesowych, takich jak digitalizacja dokumentów w celu przechowywania lub przetwarzania, oraz w zastosowaniach konsumenckich, takich jak skanowanie pokwitowań w celu zwrotu kosztów.

Stan konwersacyjnej AI 2022 XNUMX
Stan konwersacyjnej sztucznej inteligencji 2022 Co to jest konwersacyjna sztuczna inteligencja? Programowy i inteligentny sposób oferowania konwersacji i naśladowania rozmów z prawdziwymi ludźmi, za pośrednictwem technologii cyfrowej i telekomunikacyjnej

Co to jest zbieranie danych? Wszystko, co początkujący musi wiedzieć
Inteligentne modele #AI/ #ML są wszędzie, czy to predykcyjne modele opieki zdrowotnej, proaktywna diagnoza,

Co to jest etykietowanie danych? Wszystko, co początkujący musi wiedzieć
Pobierz infografikę Inteligentne modele sztucznej inteligencji muszą być intensywnie przeszkolone, aby móc identyfikować wzorce, obiekty i ostatecznie podejmować wiarygodne decyzje. Jednak przeszkoleni