



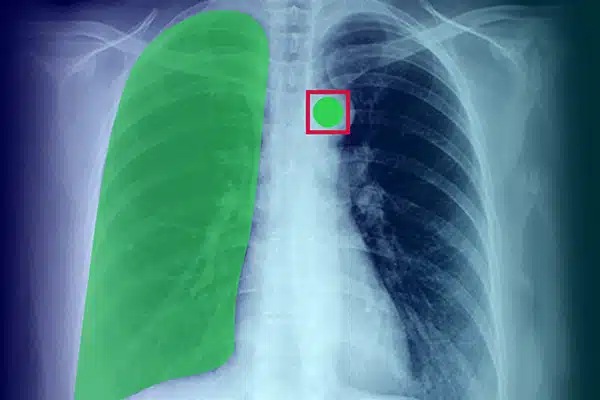
Adnotacja obrazu
Ulepsz medyczną sztuczną inteligencję, dodając adnotacje do danych wizualnych z zdjęć rentgenowskich, tomografii komputerowej i rezonansu magnetycznego. Upewnij się, że modele AI doskonale sprawdzają się w diagnostyce i leczeniu, kierując się etykietowaniem danych eksperckich. Uzyskaj lepsze wyniki leczenia pacjentów dzięki doskonałym wglądom w obrazowanie.
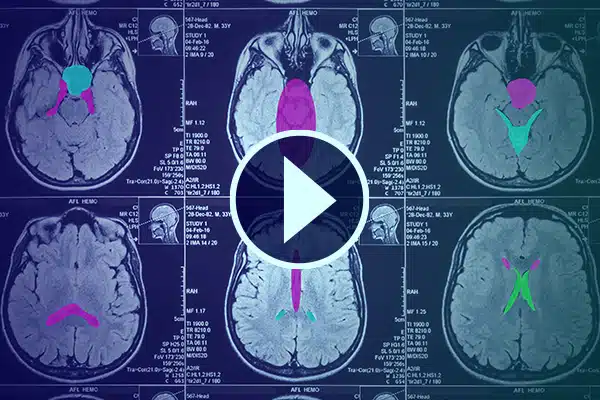
Adnotacja wideo
Zaawansowana sztuczna inteligencja w opiece zdrowotnej dzięki szczegółowym adnotacjom wideo. Udoskonalaj uczenie się sztucznej inteligencji dzięki klasyfikacjom i segmentacjom w materiałach medycznych. Ulepsz swoją chirurgiczną sztuczną inteligencję i monitorowanie pacjentów, aby usprawnić świadczenie opieki zdrowotnej i diagnostykę.
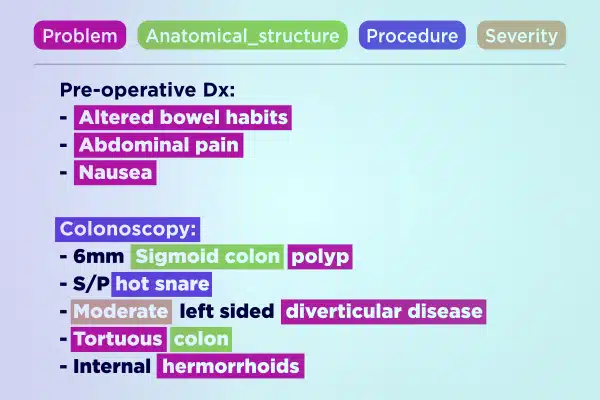
Adnotacja tekstowa
Usprawnij rozwój medycznej sztucznej inteligencji dzięki fachowym danym tekstowym z adnotacjami. Szybko analizuj i wzbogacaj ogromne ilości tekstu, od odręcznych notatek po raporty ubezpieczeniowe. Zapewnij dokładne i praktyczne spostrzeżenia na rzecz postępu w opiece zdrowotnej.

Adnotacja dźwiękowa
Wykorzystaj wiedzę NLP, aby dokładnie opisywać i oznaczać medyczne dane audio. Twórz systemy wspomagane głosem umożliwiające płynne operacje kliniczne i integruj sztuczną inteligencję z różnymi produktami opieki zdrowotnej aktywowanymi głosem. Zwiększ precyzję diagnostyki dzięki specjalistycznej selekcji danych audio.

Kodowanie medyczne
Usprawnij dokumentację medyczną, przekształcając ją w uniwersalne kody za pomocą kodowania medycznego AI. Zapewnij dokładność, zwiększ efektywność rozliczeń i wspieraj płynne świadczenie usług opieki zdrowotnej dzięki najnowocześniejszej pomocy AI w kodowaniu dokumentacji medycznej.

Faza 1: Wiedza techniczna w dziedzinie (zrozumienie zakresu i wytycznych dotyczących adnotacji)

Faza 2: Szkolenie odpowiednich zasobów dla projektu

Faza 3: Cykl opinii i kontrola jakości dokumentów z adnotacjami
Radiologia
Nasza usługa adnotacji do obrazów radiologicznych usprawnia diagnostykę AI i obejmuje dodatkową warstwę wiedzy specjalistycznej. Każde zdjęcie rentgenowskie, rezonans magnetyczny i tomografia komputerowa jest szczegółowo oznakowane i sprawdzane przez eksperta w danej dziedzinie. Ten dodatkowy etap szkolenia i przeglądu zwiększa zdolność sztucznej inteligencji do wykrywania nieprawidłowości i chorób. Zwiększa dokładność przed dostawą do naszych klientów.

Kardiologia
Nasze adnotacje obrazowe dotyczące kardiologii usprawniają diagnostykę AI. Zatrudniamy ekspertów w dziedzinie kardiologii, którzy oznaczają złożone obrazy związane z sercem i szkolą nasze modele AI. Zanim wyślemy dane do klientów, specjaliści ci sprawdzają każdy obraz, aby zapewnić najwyższą dokładność. Proces ten umożliwia AI dokładniejsze wykrywanie chorób serca.
Stomatologia
Nasza usługa adnotacji obrazów w stomatologii oznacza zdjęcia zębów w celu ulepszenia narzędzi diagnostycznych AI. Dzięki dokładnej identyfikacji próchnicy, problemów z wyrównaniem zębów i innych schorzeń stomatologicznych nasze MŚP wspomagają sztuczną inteligencję w celu poprawy wyników pacjentów i wspierają dentystów w precyzyjnym planowaniu leczenia i wczesnym wykrywaniu.


















Ludzie
Dedykowane i przeszkolone zespoły:
- Ponad 30,000 współpracowników w zakresie tworzenia danych, etykietowania i kontroli jakości Q
- Uznany Zespół Zarządzania Projektami
- Doświadczony zespół rozwoju produktu
- Zespół ds. pozyskiwania i wdrażania puli talentów

Przetwarzanie
Najwyższą wydajność procesu zapewniają:
- Solidny proces 6 Sigma Stage-Gate
- Dedykowany zespół 6 czarnych pasów Sigma – Właściciele kluczowych procesów i zgodność z jakością
- Ciągłe doskonalenie i pętla sprzężenia zwrotnego

Platforma
Opatentowana platforma oferuje korzyści:
- Kompleksowa platforma internetowa
- Nienaganna jakość
- Szybsze TAT
- Bezproblemowa dostawa



