
Sztuczna inteligencja i duże zbiory danych mają potencjał, aby znaleźć rozwiązania globalnych problemów, jednocześnie nadając priorytet lokalnym problemom i przekształcając świat na wiele głębokich sposobów. Sztuczna inteligencja zapewnia rozwiązania dla wszystkich – i we wszystkich środowiskach, od domów po miejsca pracy. Komputery AI, z Nauczanie maszynowe szkolenia, może symulować inteligentne zachowanie i rozmowy w zautomatyzowany, ale spersonalizowany sposób.
Jednak sztuczna inteligencja ma problem z włączeniem i często jest stronnicza. Na szczęście skupiając się na etyka sztucznej inteligencji może zapoczątkować nowe możliwości w zakresie dywersyfikacji i włączenia poprzez wyeliminowanie nieświadomych uprzedzeń poprzez różnorodne dane szkoleniowe.
Znaczenie różnorodności w danych szkoleniowych AI
 Różnorodność i jakość danych szkoleniowych są ze sobą powiązane, ponieważ jedno wpływa na drugie i wpływa na wynik rozwiązania opartego na sztucznej inteligencji. Sukces rozwiązania AI zależy od zróżnicowane dane jest na nim szkolony. Różnorodność danych zapobiega nadmiernemu dopasowaniu sztucznej inteligencji, co oznacza, że model działa lub uczy się tylko na podstawie danych używanych do trenowania. W przypadku nadmiernego dopasowania model AI nie może zapewnić wyników podczas testowania na danych, które nie są wykorzystywane w szkoleniu.
Różnorodność i jakość danych szkoleniowych są ze sobą powiązane, ponieważ jedno wpływa na drugie i wpływa na wynik rozwiązania opartego na sztucznej inteligencji. Sukces rozwiązania AI zależy od zróżnicowane dane jest na nim szkolony. Różnorodność danych zapobiega nadmiernemu dopasowaniu sztucznej inteligencji, co oznacza, że model działa lub uczy się tylko na podstawie danych używanych do trenowania. W przypadku nadmiernego dopasowania model AI nie może zapewnić wyników podczas testowania na danych, które nie są wykorzystywane w szkoleniu.
Obecny stan szkolenia AI dane
Nierówność lub brak różnorodności danych prowadziłaby do niesprawiedliwych, nieetycznych i nieintegracyjnych rozwiązań w zakresie sztucznej inteligencji, które mogłyby pogłębić dyskryminację. Ale w jaki sposób i dlaczego różnorodność danych jest powiązana z rozwiązaniami AI?
Nierówna reprezentacja wszystkich klas prowadzi do błędnej identyfikacji twarzy – jednym z ważnych przykładów jest Google Photos, które sklasyfikowały czarną parę jako „goryle”. A Meta podpowiada użytkownikowi oglądającemu film przedstawiający czarnych mężczyzn, czy chce „kontynuować oglądanie filmów przedstawiających naczelne”.
Na przykład niedokładna lub niewłaściwa klasyfikacja mniejszości etnicznych lub rasowych, zwłaszcza w chatbotach, może skutkować uprzedzeniami w systemach szkoleniowych AI. Według raportu z 2019 r Systemy dyskryminujące – płeć, rasa, władza w AIponad 80% nauczycieli AI to mężczyźni; badaczki AI na FB to tylko 15%, a w Google 10%.
Wpływ różnorodnych danych szkoleniowych na wydajność sztucznej inteligencji
 Pominięcie określonych grup i społeczności w reprezentacji danych może prowadzić do wypaczonych algorytmów.
Pominięcie określonych grup i społeczności w reprezentacji danych może prowadzić do wypaczonych algorytmów.
Stronniczość danych jest często przypadkowo wprowadzana do systemów danych – poprzez niedostateczne próbkowanie niektórych ras lub grup. Kiedy systemy rozpoznawania twarzy są szkolone na różnych twarzach, pomaga to modelowi zidentyfikować określone cechy, takie jak położenie narządów twarzy i różnice kolorystyczne.
Innym rezultatem niezrównoważonej częstotliwości etykiet jest to, że system może uznać mniejszość za anomalię, gdy zostanie zmuszona do wytworzenia danych wyjściowych w krótkim czasie.
Osiąganie różnorodności w danych szkoleniowych AI
Z drugiej strony generowanie zróżnicowanego zestawu danych jest również wyzwaniem. Sam brak danych dotyczących niektórych klas może prowadzić do niedostatecznej reprezentacji. Można go złagodzić, zwiększając różnorodność zespołów programistów AI pod względem umiejętności, pochodzenia etnicznego, rasy, płci, dyscypliny i innych. Co więcej, idealnym sposobem rozwiązania problemów związanych z różnorodnością danych w sztucznej inteligencji jest skonfrontowanie się z nimi od samego początku, zamiast próbować naprawić to, co zostało zrobione – wprowadzając różnorodność na etapie gromadzenia i pielęgnacji danych.
Niezależnie od szumu wokół sztucznej inteligencji, nadal zależy ona od danych zbieranych, selekcjonowanych i szkolonych przez ludzi. Wrodzona stronniczość u ludzi znajdzie odzwierciedlenie w zebranych przez nich danych, a ta nieświadoma stronniczość wkrada się również do modeli ML.
Kroki zbierania i nadzorowania różnorodnych danych treningowych
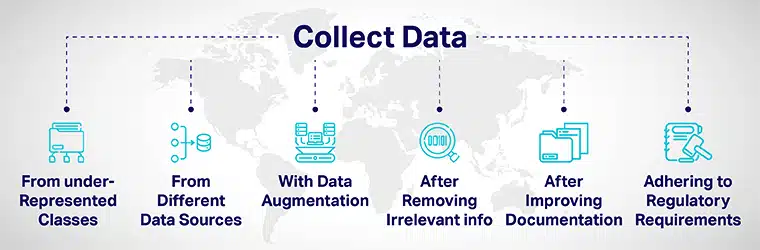
Różnorodność danych można osiągnąć poprzez:
- W przemyślany sposób dodawaj więcej danych z niedostatecznie reprezentowanych klas i udostępniaj swoje modele różnym punktom danych.
- Zbierając dane z różnych źródeł danych.
- Poprzez rozszerzanie danych lub sztuczną manipulację zbiorami danych w celu zwiększenia/włączenia nowych punktów danych wyraźnie różniących się od oryginalnych punktów danych.
- Zatrudniając kandydatów do procesu rozwoju sztucznej inteligencji, usuń z aplikacji wszystkie informacje nieistotne dla stanowiska.
- Poprawa przejrzystości i odpowiedzialności poprzez poprawę dokumentacji rozwoju i oceny modeli.
- Wprowadzenie przepisów budujących różnorodność i inkluzywność w AI systemów od podstaw. Różne rządy opracowały wytyczne, aby zapewnić różnorodność i złagodzić stronniczość sztucznej inteligencji, która może przynieść niesprawiedliwe wyniki.
[Przeczytaj także: Dowiedz się więcej o procesie gromadzenia danych szkoleniowych AI ]
Wnioski
Obecnie tylko kilka dużych firm technologicznych i centrów edukacyjnych zajmuje się wyłącznie opracowywaniem rozwiązań AI. Te elitarne przestrzenie są przesiąknięte wykluczeniem, dyskryminacją i uprzedzeniami. Są to jednak przestrzenie, w których rozwija się sztuczna inteligencja, a logika stojąca za tymi zaawansowanymi systemami sztucznej inteligencji jest pełna tych samych uprzedzeń, dyskryminacji i wykluczenia, jakie ponoszą niedostatecznie reprezentowane grupy.
Omawiając różnorodność i niedyskryminację, ważne jest, aby zastanowić się, komu przynosi ona korzyści, a komu szkodzi. Powinniśmy również przyjrzeć się, kogo stawia to w niekorzystnej sytuacji – narzucając ideę „normalnej” osoby, sztuczna inteligencja może potencjalnie narazić „innych” na ryzyko.
Omawianie różnorodności danych AI bez uznania relacji władzy, równości i sprawiedliwości nie pokaże szerszego obrazu. Aby w pełni zrozumieć zakres różnorodności danych szkoleniowych AI oraz to, w jaki sposób ludzie i sztuczna inteligencja mogą wspólnie złagodzić ten kryzys, skontaktuj się z inżynierami z firmy Shaip. Mamy różnych inżynierów AI, którzy mogą dostarczać dynamiczne i różnorodne dane dla twoich rozwiązań AI.


