
Szacuje się, że przeciętny dorosły podejmuje decyzje dotyczące życia i codziennych spraw na podstawie wcześniejszej nauki. Te z kolei wynikają z doświadczeń życiowych ukształtowanych przez sytuacje i ludzi. W dosłownym sensie sytuacje, przypadki i ludzie są niczym innym jak danymi, które trafiają do naszych umysłów. Gdy gromadzimy lata danych w formie doświadczeń, ludzki umysł ma tendencję do podejmowania bezproblemowych decyzji.
Co to oznacza? Te dane są nieuniknione w nauce.
Podobnie jak dziecko potrzebuje etykiety zwanej alfabetem, aby zrozumieć litery A, B, C, D, maszyna musi również rozumieć dane, które otrzymuje.
Właśnie to Artificial Intelligence (AI) chodzi o szkolenie. Maszyna nie różni się od dziecka, które jeszcze nie nauczyło się rzeczy z tego, czego ma się nauczyć. Maszyna nie potrafi odróżnić kota od psa czy autobusu od samochodu, ponieważ nie doświadczyły jeszcze tych przedmiotów ani nie nauczyły się, jak wyglądają.
Tak więc, dla kogoś, kto buduje samojezdny samochód, podstawową funkcją, którą należy dodać, jest zdolność systemu do rozumienia wszystkich codziennych elementów, z którymi może się spotkać samochód, tak aby pojazd mógł je zidentyfikować i podejmować odpowiednie decyzje dotyczące jazdy. To jest gdzie Dane treningowe AI wchodzi w grę.
Dziś moduły sztucznej inteligencji oferują nam wiele udogodnień w postaci silników rekomendacji, nawigacji, automatyzacji i nie tylko. Wszystko to dzieje się dzięki szkoleniu danych AI, które zostało użyte do trenowania algorytmów podczas ich tworzenia.
Dane szkoleniowe AI to podstawowy proces w budowaniu uczenie maszynowe i algorytmy AI. Jeśli tworzysz aplikację opartą na tych koncepcjach technicznych, musisz przeszkolić swoje systemy, aby zrozumieć elementy danych w celu zoptymalizowanego przetwarzania. Bez szkolenia Twój model AI będzie nieefektywny, wadliwy i potencjalnie bezcelowy.
Co to są dane szkoleniowe AI?
Dane szkoleniowe AI to starannie wyselekcjonowane i oczyszczone informacje, które są wprowadzane do systemu w celach szkoleniowych. Ten proces powoduje lub przerywa sukces modelu AI. Może pomóc w zrozumieniu, że nie wszystkie czworonożne zwierzęta na zdjęciu to psy, lub może pomóc modelowi odróżnić gniewny krzyk od radosnego śmiechu. Jest to pierwszy etap budowania modułów sztucznej inteligencji, które wymagają danych podawanych łyżką, aby nauczyć maszyny podstaw i umożliwić im naukę w miarę podawania większej ilości danych. To znowu ustępuje miejsca wydajnemu modułowi, który dostarcza precyzyjne wyniki użytkownikom końcowym.

Rozważ proces treningu danych AI jako sesję treningową dla muzyka, gdzie im więcej ćwiczy, tym lepiej osiąga piosenkę lub skalę. Jedyną różnicą jest to, że maszyny muszą najpierw zostać nauczone, czym jest instrument muzyczny. Podobnie jak muzyk, który dobrze wykorzystuje niezliczone godziny spędzone na ćwiczeniach na scenie, model AI oferuje konsumentom optymalne wrażenia po wdrożeniu.

Jakich danych potrzebuję?
Istnieją 4 podstawowe typy danych, które byłyby potrzebne, tj. Obraz, wideo, dźwięk/mowa lub tekst, aby skutecznie trenować modele uczenia maszynowego. Rodzaj potrzebnych danych będzie zależał od różnych czynników, takich jak dany przypadek użycia, złożoność trenowanych modeli, zastosowana metoda uczenia oraz różnorodność wymaganych danych wejściowych.
Ile danych jest adekwatnych?
Mówią, że uczeniu się nie ma końca, a to zdanie jest idealne w spektrum danych treningowych AI. Im więcej danych, tym lepsze wyniki. Jednak odpowiedź tak niejasna, jak to nie wystarczy, aby przekonać każdego, kto chce uruchomić aplikację opartą na sztucznej inteligencji. Ale rzeczywistość jest taka, że nie ma ogólnej zasady, formuły, indeksu lub pomiaru dokładnej ilości danych, które są potrzebne do trenowania ich zestawów danych AI.

Ekspert w dziedzinie uczenia maszynowego wyjawiłby komicznie, że należy zbudować oddzielny algorytm lub moduł, aby wywnioskować ilość danych wymaganych dla projektu. Taka jest niestety również rzeczywistość.
Teraz jest powód, dla którego niezwykle trudno jest ograniczyć ilość danych wymaganych do treningu AI. Wynika to z zawiłości samego procesu szkoleniowego. Moduł AI składa się z kilku warstw połączonych ze sobą i nakładających się na siebie fragmentów, które wpływają i uzupełniają się nawzajem.
Załóżmy na przykład, że tworzysz prostą aplikację do rozpoznawania drzewa kokosowego. Z perspektywy brzmi to dość prosto, prawda? Jednak z perspektywy sztucznej inteligencji jest to znacznie bardziej złożone.
Na samym początku maszyna jest pusta. Przede wszystkim nie wie, czym jest drzewo, nie mówiąc już o wysokim, specyficznym dla regionu, tropikalnym drzewie owocującym. W tym celu model musi zostać przeszkolony w zakresie tego, czym jest drzewo, jak odróżnić się od innych wysokich i smukłych obiektów, które mogą pojawić się w kadrze, takich jak latarnie uliczne lub słupy elektryczne, a następnie przejść do uczenia go niuansów drzewa kokosowego. Gdy moduł uczenia maszynowego nauczy się, czym jest drzewo kokosowe, można śmiało założyć, że wie, jak je rozpoznać.
Ale tylko wtedy, gdy nakarmisz obraz figowca, zdasz sobie sprawę, że system błędnie zidentyfikował drzewo figowe jako drzewo kokosowe. W przypadku systemu wszystko, co jest wysokie i ma zbite liście, to drzewo kokosowe. Aby to wyeliminować, system musi teraz dokładnie rozpoznać każde drzewo, które nie jest drzewem kokosowym. Jeśli jest to proces dla prostej jednokierunkowej aplikacji z tylko jednym wynikiem, możemy sobie tylko wyobrazić złożoność aplikacji opracowanych dla opieki zdrowotnej, finansów i nie tylko.



Jak poprawić jakość danych?
Jakość danych jest wprost proporcjonalna do jakości wyników. Dlatego bardzo dokładne modele wymagają wysokiej jakości zestawów danych do uczenia. Jest jednak pewien haczyk. Jak na koncepcję, która opiera się na precyzji i dokładności, pojęcie jakości jest często dość niejasne.
Dane wysokiej jakości brzmią mocno i wiarygodnie, ale co to właściwie oznacza?
Czym jest przede wszystkim jakość?
Cóż, podobnie jak same dane, które wprowadzamy do naszych systemów, również jakość ma wiele czynników i parametrów z nią związanych. Jeśli skontaktujesz się z ekspertami AI lub weteranami uczenia maszynowego, mogą oni udostępnić dowolną kombinację wysokiej jakości danych, co jest –

- Mundur – dane pochodzące z jednego konkretnego źródła lub jednolitość w zbiorach danych pochodzących z wielu źródeł
- Wszechstronny – dane obejmujące wszystkie możliwe scenariusze, nad którymi ma pracować Twój system
- Stały monitoring – każdy bajt danych ma podobny charakter
- Istotnych – dane, które pozyskujesz i dostarczasz, są podobne do Twoich wymagań i oczekiwanych wyników oraz
- Różnorodność – masz kombinację wszystkich rodzajów danych, takich jak audio, wideo, obraz, tekst i inne
Teraz, gdy rozumiemy, co oznacza jakość w jakości danych, szybko przyjrzyjmy się różnym sposobom, w jakie możemy zapewnić jakość zbieranie danych i pokolenie.
Co wpływa na jakość danych treningowych?
Istnieją trzy główne czynniki, które mogą pomóc w przewidywaniu pożądanego poziomu jakości modeli AI/ML. Trzy kluczowe czynniki to ludzie, proces i platforma, które mogą stworzyć lub zepsuć twój projekt AI.
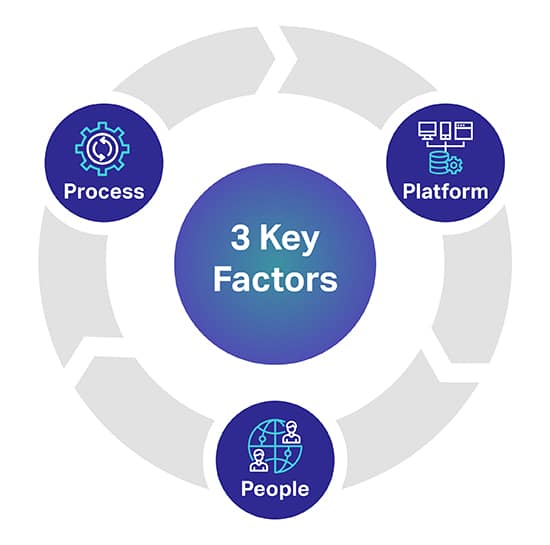
Platforma: Do pozyskiwania, transkrypcji i opisywania różnorodnych zestawów danych potrzebna jest kompletna, prawnie zastrzeżona platforma typu „human-in-the-loop”, umożliwiająca pomyślne wdrażanie najbardziej wymagających inicjatyw związanych ze sztuczną inteligencją i ML. Platforma jest również odpowiedzialna za zarządzanie pracownikami oraz maksymalizację jakości i przepustowości
Ludzie: Aby sztuczna inteligencja myślała mądrzej, potrzeba ludzi, którzy są jednymi z najmądrzejszych umysłów w branży. Aby skalować, potrzebujesz tysięcy takich profesjonalistów na całym świecie do transkrypcji, etykietowania i komentowania wszystkich typów danych.
Proces: Dostarczanie danych o złotym standardzie, które są spójne, kompletne i dokładne, to skomplikowana praca. Ale to jest to, co zawsze będziesz musiał dostarczać, aby przestrzegać najwyższych standardów jakości, a także rygorystycznych i sprawdzonych kontroli jakości i punktów kontrolnych.
Skąd pozyskujesz dane szkoleniowe AI?
W przeciwieństwie do naszej poprzedniej sekcji, mamy tutaj bardzo dokładny wgląd. Dla tych z Was, którzy chcą pozyskać dane
lub jeśli jesteś w trakcie zbierania wideo, zbierania obrazów, zbierania tekstu i innych, są trzy
główne drogi, z których możesz pozyskiwać swoje dane.
Zbadajmy je indywidualnie.
Darmowe źródła
Darmowe źródła to drogi, które są mimowolnymi repozytoriami ogromnych ilości danych. To dane, które po prostu leżą tam na powierzchni za darmo. Niektóre z bezpłatnych zasobów obejmują:

- Zbiory danych Google, w których w 250 roku opublikowano ponad 2020 milionów zestawów danych
- Fora takie jak Reddit, Quora i inne, które są zasobnymi źródłami danych. Poza tym społeczności zajmujące się nauką danych i sztuczną inteligencją na tych forach mogą również pomóc w uzyskaniu określonych zestawów danych, gdy się z nimi skontaktujesz.
- Kaggle to kolejne bezpłatne źródło, w którym oprócz bezpłatnych zestawów danych można znaleźć zasoby uczenia maszynowego.
- Wymieniliśmy również bezpłatne otwarte zbiory danych, aby rozpocząć szkolenie modeli AI
Chociaż te drogi są bezpłatne, ostatecznie poświęcisz czas i wysiłek. Dane z darmowych źródeł są wszędzie i musisz poświęcić wiele godzin pracy na pozyskiwanie, czyszczenie i dostosowywanie ich do swoich potrzeb.
Jedną z innych ważnych wskazówek, o których należy pamiętać, jest to, że niektóre dane z bezpłatnych źródeł nie mogą być również wykorzystywane do celów komercyjnych. To wymaga licencjonowanie danych.
Otwarte zbiory danych – używać czy nie?
 Otwarte zestawy danych to publicznie dostępne zestawy danych, których można używać w projektach uczenia maszynowego. Nie ma znaczenia, czy potrzebujesz zestawu danych audio, wideo, obrazu czy tekstu, dostępne są otwarte zestawy danych dla wszystkich formularzy i klas danych.
Otwarte zestawy danych to publicznie dostępne zestawy danych, których można używać w projektach uczenia maszynowego. Nie ma znaczenia, czy potrzebujesz zestawu danych audio, wideo, obrazu czy tekstu, dostępne są otwarte zestawy danych dla wszystkich formularzy i klas danych.
Na przykład istnieje zbiór danych recenzji produktów Amazon, który zawiera ponad 142 miliony recenzji użytkowników od 1996 do 2014 roku. W przypadku obrazów masz doskonałe źródło, takie jak Google Open Images, w którym możesz pozyskać zestawy danych z ponad 9 milionów zdjęć. Google ma również skrzydło o nazwie Machine Perception, które oferuje blisko 2 miliony klipów audio trwających dziesięć sekund.
Pomimo dostępności tych zasobów (i innych), ważnym czynnikiem, który często jest pomijany, są warunki związane z ich użytkowaniem. Z pewnością są one publiczne, ale istnieje cienka granica między naruszeniem a dozwolonym użyciem. Każdy zasób ma swój własny stan i jeśli badasz te opcje, sugerujemy ostrożność. Dzieje się tak dlatego, że pod pretekstem preferowania bezpłatnych dróg możesz ponieść procesy sądowe i powiązane wydatki.
Prawdziwe koszty danych szkoleniowych AI AI
Tylko pieniądze, które wydajesz na pozyskiwanie danych lub generowanie danych we własnym zakresie, nie są tym, co powinieneś brać pod uwagę. Musimy wziąć pod uwagę elementy liniowe, takie jak czas i wysiłek poświęcony na rozwój systemów AI i koszt z perspektywy transakcyjnej. nie komplementuje drugiego.
Czas poświęcony na pozyskiwanie i opisywanie danych
Czynniki takie jak geografia, dane demograficzne rynku i konkurencja w Twojej niszy utrudniają dostępność odpowiednich zbiorów danych. Czas spędzony na ręcznym wyszukiwaniu danych jest marnowaniem czasu na szkolenie systemu AI. Gdy uda Ci się pozyskać dane, opóźnisz szkolenie, poświęcając czas na adnotowanie danych, aby Twoja maszyna mogła zrozumieć, co jest zasilane.
Cena zbierania i opisywania danych
Koszty ogólne (wewnętrzne zbieracze danych, adnotatorzy, konserwacja sprzętu, infrastruktura techniczna, subskrypcje narzędzi SaaS, tworzenie zastrzeżonych aplikacji) muszą być obliczane podczas pozyskiwania danych AI
Koszt złych danych
Złe dane mogą kosztować morale zespołu firmy, przewagę konkurencyjną i inne namacalne konsekwencje, które pozostają niezauważone. Złe dane definiujemy jako dowolny zbiór danych, który jest nieczysty, nieprzetworzony, nieistotny, nieaktualny, niedokładny lub pełen błędów ortograficznych. Złe dane mogą zepsuć model sztucznej inteligencji, wprowadzając stronniczość i psując algorytmy z wypaczonymi wynikami.
Koszty zarządzania
Wszystkie koszty związane z administracją Twojej organizacji lub przedsiębiorstwa, rzeczowe i niematerialne koszty zarządzania są często najdroższymi wydatkami na zarządzanie.

Co dalej po pozyskiwaniu danych?
Gdy już masz zestaw danych w ręku, następnym krokiem jest dodanie do niego adnotacji lub etykiety. Po wszystkich skomplikowanych zadaniach masz czyste, surowe dane. Maszyna nadal nie może zrozumieć danych, które posiadasz, ponieważ nie są one opatrzone adnotacjami. Tu zaczyna się pozostała część prawdziwego wyzwania.
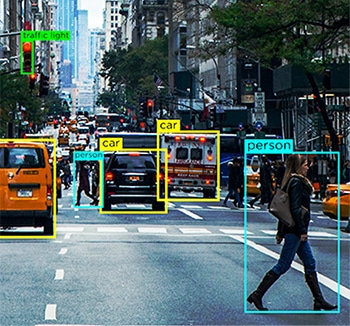
Jak wspomnieliśmy, maszyna potrzebuje danych w formacie, który może zrozumieć. To właśnie robi adnotacja danych. Pobiera surowe dane i dodaje warstwy etykiet i znaczników, aby pomóc modułowi dokładnie zrozumieć każdy element danych.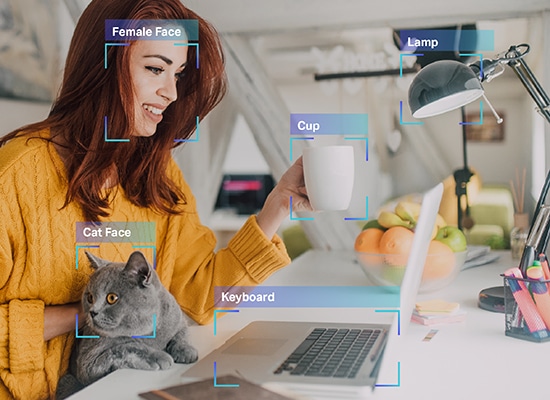
Na przykład w tekście etykietowanie danych informuje system AI o składni gramatycznej, częściach mowy, przyimkach, interpunkcjach, emocjach, sentymentach i innych parametrach związanych ze zrozumieniem maszynowym. W ten sposób chatboty lepiej rozumieją ludzkie rozmowy i tylko wtedy, gdy to robią, mogą lepiej naśladować ludzkie interakcje również poprzez swoje odpowiedzi.
Jakkolwiek nieuniknione, jak się wydaje, jest to również niezwykle czasochłonne i żmudne. Niezależnie od skali Twojej firmy czy jej ambicji, czas potrzebny na adnotację danych jest ogromny.
Dzieje się tak przede wszystkim dlatego, że obecni pracownicy muszą poświęcić czas w swoim codziennym harmonogramie na dodawanie adnotacji do danych, jeśli nie masz specjalistów od adnotacji danych. Musisz więc wezwać członków swojego zespołu i przydzielić to jako dodatkowe zadanie. Im bardziej się opóźnia, tym dłużej trwa trenowanie modeli AI.
Chociaż istnieją bezpłatne narzędzia do adnotacji danych, nie oznacza to, że proces ten jest czasochłonny.
W tym miejscu wkraczają dostawcy adnotacji danych, tacy jak Shaip. Sprowadzają ze sobą dedykowany zespół specjalistów od adnotacji danych, którzy skupiają się tylko na Twoim projekcie. Oferują Ci rozwiązania w taki sposób, w jaki chcesz, dla Twoich potrzeb i wymagań. Poza tym możesz ustalić z nimi ramy czasowe i zażądać wykonania pracy w tym konkretnym przedziale czasowym.
Jedną z głównych korzyści jest to, że członkowie Twojego wewnętrznego zespołu mogą nadal koncentrować się na tym, co jest ważniejsze dla Twoich operacji i projektu, podczas gdy eksperci wykonują za Ciebie swoją pracę polegającą na dodawaniu adnotacji i oznaczaniu etykietami danych. .
Dzięki outsourcingowi można zapewnić optymalną jakość, minimalny czas i maksymalną precyzję.