
Sztuczna inteligencja, duże zbiory danych i uczenie maszynowe nadal wpływają na decydentów, firmy, naukę, domy mediowe i różne branże na całym świecie. Raporty sugerują, że globalny wskaźnik adopcji sztucznej inteligencji wynosi obecnie ok % 35 w 2022 – ogromny wzrost o 4% od 2021 r. Podobno dodatkowe 42% firm bada liczne korzyści płynące ze sztucznej inteligencji dla ich działalności.
Wspieranie wielu inicjatyw AI i Nauczanie maszynowe rozwiązania to dane. Sztuczna inteligencja może być tylko tak dobra, jak dane zasilające algorytm. Niska jakość danych może skutkować niską jakością wyników i niedokładnymi prognozami.
Chociaż wiele uwagi poświęcono rozwojowi rozwiązań ML i AI, brakuje świadomości tego, co kwalifikuje się jako zestaw danych wysokiej jakości. W tym artykule poruszamy się po osi czasu wysokiej jakości dane szkoleniowe AI i określ przyszłość sztucznej inteligencji poprzez zrozumienie gromadzenia danych i szkolenia.
Definicja danych treningowych AI
Podczas budowania rozwiązania ML liczy się ilość i jakość zestawu danych szkoleniowych. System ML nie tylko wymaga dużych ilości dynamicznych, obiektywnych i cennych danych szkoleniowych, ale także potrzebuje ich dużo.
Ale czym są dane szkoleniowe AI?
Dane szkoleniowe AI to zbiór oznaczonych danych służących do uczenia algorytmu uczenia maszynowego w celu wykonywania dokładnych prognoz. System ML stara się rozpoznawać i identyfikować wzorce, rozumieć relacje między parametrami, podejmować niezbędne decyzje i oceniać je na podstawie danych treningowych.
Weźmy na przykład samochody autonomiczne. Szkoleniowy zestaw danych dla samojezdnego modelu ML powinien zawierać oznaczone obrazy i filmy przedstawiające samochody, pieszych, znaki drogowe i inne pojazdy.
Krótko mówiąc, aby poprawić jakość algorytmu ML, potrzebujesz dużej ilości dobrze ustrukturyzowanych, opatrzonych adnotacjami i oznaczonych danych treningowych.
Znaczenie wysokiej jakości danych treningowych i ich ewolucja
Wysokiej jakości dane szkoleniowe to kluczowy wkład w tworzenie aplikacji AI i ML. Dane są zbierane z różnych źródeł i prezentowane w niezorganizowanej formie, nieodpowiedniej do celów uczenia maszynowego. Wysokiej jakości dane szkoleniowe — oznaczone, opatrzone adnotacjami i oznaczone — są zawsze w zorganizowanym formacie — idealnym do szkolenia ML.
Wysokiej jakości dane treningowe ułatwiają systemowi ML rozpoznawanie obiektów i klasyfikowanie ich według z góry określonych cech. Zestaw danych może dawać złe wyniki modelu, jeśli klasyfikacja nie jest dokładna.
Wczesne dni danych szkoleniowych AI
Pomimo dominacji sztucznej inteligencji w obecnym świecie biznesu i badań, wczesne dni przed dominacją ML Artificial Intelligence był całkiem inny.
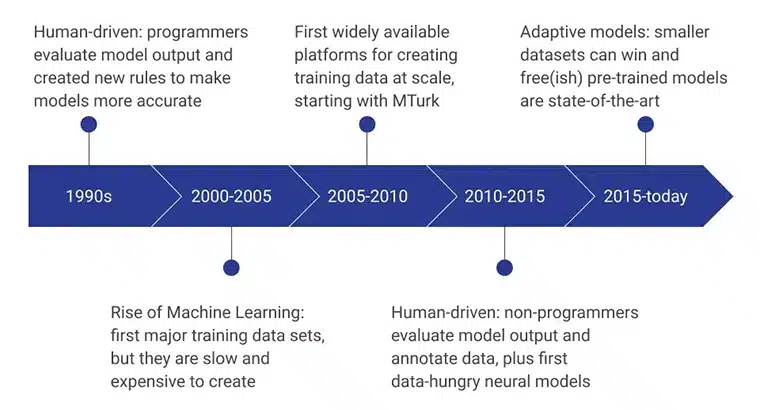
Początkowe etapy danych szkoleniowych AI były obsługiwane przez programistów-ludzi, którzy oceniali dane wyjściowe modelu, konsekwentnie opracowując nowe reguły, dzięki którym model był bardziej wydajny. W latach 2000 – 2005 powstał pierwszy duży zbiór danych i był to niezwykle powolny, zależny od zasobów i kosztowny proces. Doprowadziło to do opracowania zestawów danych szkoleniowych na dużą skalę, a MTurk firmy Amazon odegrał znaczącą rolę w zmianie postrzegania gromadzenia danych przez ludzi. Jednocześnie rozpoczęło się oznaczanie i adnotacje przez ludzi.
Kilka następnych lat koncentrowało się na tworzeniu i ocenie modeli danych przez osoby niebędące programistami. Obecnie nacisk kładziony jest na wstępnie wytrenowane modele opracowane przy użyciu zaawansowanych metod gromadzenia danych treningowych.
Ilość ponad jakość
Oceniając integralność zestawów danych szkoleniowych AI w ciągu dnia, analitycy danych skupiali się na Ilość danych szkoleniowych AI nad jakością.
Na przykład panowało powszechne błędne przekonanie, że duże bazy danych dostarczają dokładnych wyników. Uważano, że sama ilość danych jest dobrym wskaźnikiem wartości danych. Ilość to tylko jeden z podstawowych czynników decydujących o wartości zbioru danych – uznano rolę jakości danych.
Świadomość, że jakość danych zależała od kompletności danych, wiarygodności, ważności, dostępności i terminowości. Co najważniejsze, przydatność danych do projektu determinowała jakość zebranych danych.
Ograniczenia wczesnych systemów AI z powodu słabych danych treningowych
Słabe dane szkoleniowe w połączeniu z brakiem zaawansowanych systemów obliczeniowych były jedną z przyczyn kilku niespełnionych obietnic wczesnych systemów AI.
Ze względu na brak wysokiej jakości danych treningowych rozwiązania ML nie były w stanie dokładnie zidentyfikować wzorców wizualnych hamujących rozwój badań neuronowych. Chociaż wielu badaczy dostrzegało obietnicę rozpoznawania języka mówionego, badania lub rozwój narzędzi do rozpoznawania mowy nie mogły przynieść rezultatu z powodu braku zbiorów danych dotyczących mowy. Kolejną poważną przeszkodą w opracowywaniu wysokiej klasy narzędzi sztucznej inteligencji był brak możliwości obliczeniowych i pamięci masowej komputerów.
Przejście do danych treningowych wysokiej jakości
Nastąpiła wyraźna zmiana w świadomości, że jakość zbioru danych ma znaczenie. Aby system uczenia maszynowego dokładnie naśladował ludzką inteligencję i możliwości podejmowania decyzji, musi działać na dużej ilości danych szkoleniowych o wysokiej jakości.
Pomyśl o swoich danych ML jako o ankiecie – im większa próbka danych rozmiar, tym lepsza prognoza. Jeśli przykładowe dane nie obejmują wszystkich zmiennych, mogą nie rozpoznawać wzorców lub wyciągać niedokładne wnioski.
Postępy w technologii sztucznej inteligencji i potrzeba lepszych danych szkoleniowych
 Postępy w technologii sztucznej inteligencji zwiększają zapotrzebowanie na wysokiej jakości dane szkoleniowe.
Postępy w technologii sztucznej inteligencji zwiększają zapotrzebowanie na wysokiej jakości dane szkoleniowe.Zrozumienie, że lepsze dane treningowe zwiększają szansę na niezawodne modele ML, dało początek lepszym metodologiom gromadzenia danych, adnotacji i etykietowania. Jakość i trafność danych miały bezpośredni wpływ na jakość modelu AI.
 Postępy w technologii sztucznej inteligencji zwiększają zapotrzebowanie na wysokiej jakości dane szkoleniowe.
Postępy w technologii sztucznej inteligencji zwiększają zapotrzebowanie na wysokiej jakości dane szkoleniowe.Większy nacisk na jakość i dokładność danych
Aby model ML zaczął zapewniać dokładne wyniki, jest zasilany wysokiej jakości zestawami danych, które przechodzą przez iteracyjne etapy udoskonalania danych.
Na przykład człowiek może być w stanie rozpoznać określoną rasę psa w ciągu kilku dni po zapoznaniu się z rasą – na podstawie zdjęć, filmów lub osobiście. Ludzie czerpią ze swojego doświadczenia i powiązanych informacji, aby zapamiętać i wyciągnąć tę wiedzę, gdy jest to konieczne. Jednak nie działa to tak łatwo dla maszyny. Maszyna musi być zasilana wyraźnie opisanymi i oznaczonymi obrazami – setkami lub tysiącami – tej konkretnej rasy i innych ras, aby mogła nawiązać połączenie.
Model sztucznej inteligencji przewiduje wynik, korelując informacje przeszkolone z informacjami przedstawionymi w programie Prawdziwy świat. Algorytm staje się bezużyteczny, jeśli dane treningowe nie zawierają odpowiednich informacji.
Znaczenie zróżnicowanych i reprezentatywnych danych treningowych
Większa różnorodność danych zwiększa również kompetencje, zmniejsza stronniczość i zwiększa sprawiedliwą reprezentację wszystkich scenariuszy. Jeśli model AI jest trenowany przy użyciu jednorodnego zbioru danych, możesz być pewien, że nowa aplikacja będzie działać tylko w określonym celu i służyć określonej populacji.Zbiór danych może być ukierunkowany na określoną populację, rasę, płeć, wybory i opinie intelektualne, co może prowadzić do niedokładnego modelu.
Ważne jest, aby zapewnić, że cały przebieg procesu gromadzenia danych, w tym wybór puli tematów, kuracja, adnotacja i etykietowanie, jest odpowiednio zróżnicowany, zrównoważony i reprezentatywny dla populacji.
 Większa różnorodność danych zwiększa również kompetencje, zmniejsza stronniczość i zwiększa sprawiedliwą reprezentację wszystkich scenariuszy. Jeśli model AI jest trenowany przy użyciu jednorodnego zbioru danych, możesz być pewien, że nowa aplikacja będzie działać tylko w określonym celu i służyć określonej populacji.
Większa różnorodność danych zwiększa również kompetencje, zmniejsza stronniczość i zwiększa sprawiedliwą reprezentację wszystkich scenariuszy. Jeśli model AI jest trenowany przy użyciu jednorodnego zbioru danych, możesz być pewien, że nowa aplikacja będzie działać tylko w określonym celu i służyć określonej populacji.Przyszłość danych szkoleniowych AI
Przyszły sukces modeli AI zależy od jakości i ilości danych szkoleniowych wykorzystywanych do uczenia algorytmów uczenia maszynowego. Bardzo ważne jest, aby zdać sobie sprawę, że ta zależność między jakością i ilością danych jest specyficzna dla zadania i nie ma jednoznacznej odpowiedzi.
Ostatecznie adekwatność zestawu danych szkoleniowych jest definiowana przez jego zdolność do niezawodnego działania w celu, w którym został zbudowany.
Postępy w gromadzeniu danych i technikach adnotacji
Ponieważ uczenie maszynowe jest wrażliwe na podawane dane, niezbędne jest usprawnienie zasad gromadzenia danych i adnotacji. Błędy w gromadzeniu danych, kuracji, wprowadzaniu w błąd, niekompletnych pomiarach, niedokładnej treści, powielaniu danych i błędnych pomiarach przyczyniają się do niewystarczającej jakości danych.
Zautomatyzowane gromadzenie danych poprzez eksplorację danych, pobieranie danych z sieci i ekstrakcję danych toruje drogę do szybszego generowania danych. Ponadto wstępnie spakowane zestawy danych działają jako szybka technika gromadzenia danych.
Crowdsourcing to kolejna przełomowa metoda gromadzenia danych. Chociaż nie można zagwarantować prawdziwości danych, jest to doskonałe narzędzie do gromadzenia publicznego wizerunku. Wreszcie specjalistyczne zbieranie danych eksperci dostarczają również dane pozyskiwane do określonych celów.
Większy nacisk na względy etyczne w danych szkoleniowych
Wraz z szybkim postępem w sztucznej inteligencji pojawiło się kilka problemów etycznych, zwłaszcza w zakresie gromadzenia danych szkoleniowych. Niektóre kwestie etyczne związane z gromadzeniem danych szkoleniowych obejmują świadomą zgodę, przejrzystość, stronniczość i prywatność danych.Ponieważ dane obejmują teraz wszystko, od obrazów twarzy, odcisków palców, nagrań głosu i innych krytycznych danych biometrycznych, niezwykle ważne staje się zapewnienie przestrzegania praktyk prawnych i etycznych w celu uniknięcia kosztownych procesów sądowych i uszczerbku na reputacji.
Potencjał jeszcze lepszej jakości i zróżnicowanych danych treningowych w przyszłości
Potencjał jest ogromny wysokiej jakości i zróżnicowane dane szkoleniowe w przyszłości. Dzięki świadomości jakości danych i dostępności dostawców danych, którzy zaspokajają wymagania jakościowe rozwiązań AI.
Obecni dostawcy danych są biegli w wykorzystywaniu przełomowych technologii do etycznego i legalnego pozyskiwania ogromnych ilości różnorodnych zbiorów danych. Mają również wewnętrzne zespoły do oznaczania, opisywania i prezentowania danych dostosowanych do różnych projektów ML.
 Wraz z szybkim postępem w sztucznej inteligencji pojawiło się kilka problemów etycznych, zwłaszcza w zakresie gromadzenia danych szkoleniowych. Niektóre kwestie etyczne związane z gromadzeniem danych szkoleniowych obejmują świadomą zgodę, przejrzystość, stronniczość i prywatność danych.
Wraz z szybkim postępem w sztucznej inteligencji pojawiło się kilka problemów etycznych, zwłaszcza w zakresie gromadzenia danych szkoleniowych. Niektóre kwestie etyczne związane z gromadzeniem danych szkoleniowych obejmują świadomą zgodę, przejrzystość, stronniczość i prywatność danych.Wnioski
Ważne jest, aby współpracować z niezawodnymi dostawcami, którzy doskonale rozumieją dane i jakość opracowywać wysokiej klasy modele AI. Shaip jest wiodącą firmą zajmującą się adnotacjami, która jest biegła w dostarczaniu niestandardowych rozwiązań w zakresie danych, które spełniają potrzeby i cele projektów AI. Nawiąż z nami współpracę i odkryj kompetencje, zaangażowanie i współpracę, które oferujemy.


