
Sztuczna inteligencja rewolucjonizuje przemysł muzyczny, oferując zautomatyzowane narzędzia do komponowania, masteringu i występów. Algorytmy sztucznej inteligencji generują nowe kompozycje, przewidują hity i personalizują wrażenia słuchacza, zmieniając produkcję, dystrybucję i konsumpcję muzyki. Ta rozwijająca się technologia stwarza zarówno ekscytujące możliwości, jak i trudne dylematy etyczne.
Modele uczenia maszynowego (ML) wymagają danych treningowych do skutecznego działania, podobnie jak kompozytor potrzebuje nut do napisania symfonii. W świecie muzyki, gdzie melodia, rytm i emocje przeplatają się ze sobą, nie można przecenić znaczenia wysokiej jakości danych treningowych. Jest to podstawa opracowywania solidnych i dokładnych modeli ML muzyki do analizy predykcyjnej, klasyfikacji gatunków lub automatycznej transkrypcji.
Dane, siła napędowa modeli ML
Uczenie maszynowe jest z natury oparte na danych. Te modele obliczeniowe uczą się wzorców na podstawie danych, umożliwiając im przewidywanie lub podejmowanie decyzji. W przypadku muzycznych modeli uczenia maszynowego dane treningowe często zawierają zdigitalizowane ścieżki muzyczne, teksty piosenek, metadane lub kombinację tych elementów. Jakość, ilość i różnorodność tych danych znacząco wpływa na efektywność modelu.

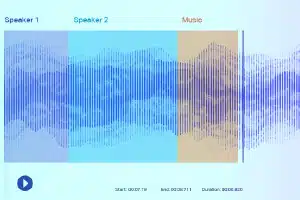
Etykietowanie dźwiękowe
Dzięki etykietom dźwiękowym osoby dokonujące adnotacji danych otrzymują nagranie i muszą oddzielić wszystkie potrzebne dźwięki i oznaczyć je etykietami. Mogą to być na przykład określone słowa kluczowe lub dźwięk określonego instrumentu muzycznego.

Klasyfikacja muzyczna
Adnotatorzy danych mogą oznaczać gatunki lub instrumenty w tego rodzaju adnotacjach dźwiękowych. Klasyfikacja muzyki jest bardzo przydatna do organizowania bibliotek muzycznych i ulepszania rekomendacji użytkowników.

Segmentacja poziomu fonetycznego
Oznaczenie i klasyfikacja segmentów fonetycznych na falach i spektrogramach nagrań osób śpiewających acapella.
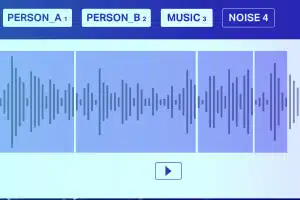
Klasyfikacja dźwięku
Z wyjątkiem ciszy/białego szumu plik audio zazwyczaj składa się z następujących typów dźwięków: Mowa, Bełkot, Muzyka i Szum. Dokładnie dodawaj notatki muzyczne, aby uzyskać większą dokładność.
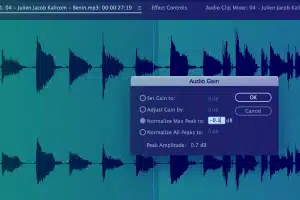
Przechwytywanie informacji o metadanych
Przechwyć ważne informacje, takie jak czas rozpoczęcia, czas zakończenia, identyfikator segmentu, poziom głośności, podstawowy typ dźwięku, kod języka, identyfikator mówcy i inne konwencje transkrypcji itp.


