
Czy zastanawiałeś się kiedyś, jak chatboty i wirtualni asystenci budzą się, gdy mówisz „Hej Siri” lub „Alexa”? Dzieje się tak ze względu na gromadzenie wypowiedzi tekstowych lub wyzwalanie słów wbudowanych w oprogramowanie, które aktywuje system, gdy tylko usłyszy zaprogramowane słowo budzące.
Jednak cały proces tworzenia dźwięków i danych wypowiedzi nie jest taki prosty. Jest to proces, który należy przeprowadzić odpowiednią techniką, aby uzyskać pożądane rezultaty. Dlatego ten blog pokaże drogę do tworzenia dobrych wypowiedzi/słów wyzwalających, które bezproblemowo współpracują z Twoją konwersacyjną sztuczną inteligencją.
Czym są wypowiedzi?
Wypowiedzi można nazwać frazami lub słowami wyzwalającymi używanymi do aktywowania modelu sztucznej inteligencji. Gdy Twój model sztucznej inteligencji wykryje słowo budzące, automatycznie zaczyna rejestrować następne żądanie użytkownika i odpowiada odpowiednią akcją lub odpowiedzią.
Wypowiedź wykorzystuje koncepcję głębokiego uczenia się, aby nauczyć oprogramowanie rozpoznawania słów budzących. Gdy słowo budzące aktywuje oprogramowanie, system rozpoczyna przechwytywanie, dekodowanie i obsługę żądania. Gdy nie jest używany, system pasywnie nasłuchuje słów wyzwalających.
Aby oprogramowanie AI mogło uzyskiwać dokładne wyniki, niezbędne jest uchwycenie mnóstwa różnych wypowiedzi dla każdego celu. Pomaga w lepszym szkoleniu modelu AI.
[Przeczytaj także: Czy chcesz wiedzieć, jak Siri i Alexa Cię rozumieją?]
Punkty do zapamiętania podczas tworzenia repozytorium wypowiedzi
Teraz, gdy wiemy, że szkolenie jest ważne dla modeli AI, następną rzeczą, którą należy wiedzieć, jest dostarczanie wypowiedzi do modeli AI. Zwykle tworzone jest repozytorium wypowiedzi, aby szkolić konwersacyjne AI.
Jest jednak kilka rzeczy, o których należy pamiętać budując repozytoria wypowiedzi. Oto rzeczy do rozważenia:
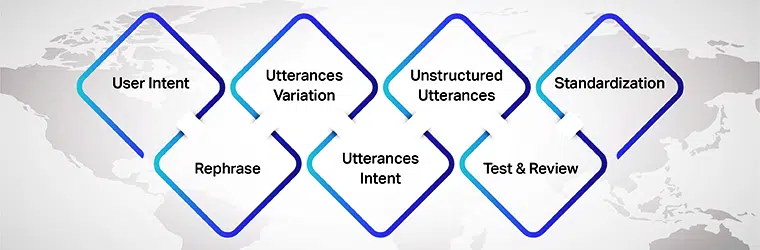
Intencja użytkownika
Przede wszystkim, przygotowując wypowiedzi dla swojego modelu AI, upewnij się, że rozumiesz intencje użytkownika, dla którego tworzysz zbiory danych. Musisz poznać różne wypowiedzi, które użytkownicy mogą wprowadzać podczas rozmowy z modelem AI.
Wariacja wypowiedzi
Odmiany są istotną częścią tego procesu, ponieważ im więcej odmian dla każdego zamiaru, tym lepsze wyniki osiągniesz. Dlatego upewnij się, że tworzysz wiele odmian wypowiedzi użytkowników. Możesz to zrobić przez
- Tworzenie krótkich, średnich i dużych zdań dla tych samych zdań.
- Zmiana słów i długości zdań.
- Używając unikalnych słów.
- Pluralizowanie zdań.
- Mieszanie gramatyki.



