
Duże modele językowe zyskały ostatnio ogromne znaczenie po tym, jak ich wysoce kompetentny przypadek użycia ChatGPT odniósł z dnia na dzień sukces. Widząc sukces ChatGPT i innych ChatBotów, wiele osób i organizacji zainteresowało się badaniem technologii, która napędza takie oprogramowanie.
Duże modele językowe są podstawą tego oprogramowania, które umożliwia działanie różnych aplikacji do przetwarzania języka naturalnego, takich jak tłumaczenie maszynowe, rozpoznawanie mowy, odpowiadanie na pytania i streszczanie tekstu. Dowiedzmy się więcej o LLM i o tym, jak możesz go zoptymalizować, aby uzyskać najlepsze wyniki.
Co to są duże modele językowe lub ChatGPT?
Duże modele językowe to model uczenia maszynowego, który wykorzystuje sztuczne sieci neuronowe i duże silosy danych do zasilania aplikacji NLP. Po szkoleniu na dużych ilościach danych LLM zyskuje możliwość uchwycenia różnych złożoności języka naturalnego, które następnie wykorzystuje do:
- Generowanie nowego tekstu
- Podsumowanie artykułów i fragmentów
- Ekstrakcja danych
- Przepisywanie lub parafrazowanie tekstu
- Klasyfikacja danych
Niektóre popularne przykłady LLM to BERT, Chat GPT-3 i XLNet. Modele te są szkolone na setkach milionów tekstów i mogą zapewnić wartościowe rozwiązania dla wszystkich typów odrębnych zapytań użytkowników.
Popularne przypadki użycia dużych modeli językowych
Oto niektóre z najlepszych i najbardziej rozpowszechnionych przypadków użycia LLM:
Generowanie tekstu
Duże modele językowe wykorzystują sztuczną inteligencję i wiedzę z zakresu lingwistyki komputerowej do automatycznego generowania tekstów w języku naturalnym i spełniania różnych komunikatywnych wymagań użytkowników, takich jak pisanie artykułów, piosenek, a nawet czatowanie z użytkownikami.
Tłumaczenie maszynowe
LLM mogą być również używane do tłumaczenia tekstu między dowolnymi dwoma językami. Modele wykorzystują algorytmy głębokiego uczenia, takie jak rekurencyjne sieci neuronowe, do uczenia się struktury językowej języka źródłowego i docelowego. W związku z tym służą do tłumaczenia tekstu źródłowego na język docelowy.
Tworzenie treści
LLM umożliwiły teraz maszynom tworzenie spójnych i logicznych treści, które można wykorzystać do generowania postów na blogach, artykułów i innych form treści. Modele wykorzystują swoją rozległą wiedzę z zakresu głębokiego uczenia się, aby zrozumieć i uporządkować treść w unikalnym i czytelnym dla użytkowników formacie.
Analiza sentymentów
Jest to ekscytujący przypadek użycia dużych modeli językowych, w których model jest szkolony w celu identyfikowania i klasyfikowania stanów emocjonalnych i uczuć w tekście oznaczonym etykietą. Oprogramowanie może wykrywać emocje, takie jak pozytywność, negatywność, neutralność i inne złożone nastroje, które mogą pomóc w uzyskaniu wglądu w opinie i recenzje klientów na temat różnych produktów i usług.
Rozumienie, podsumowanie i klasyfikacja tekstu
LLM zapewniają praktyczne ramy dla oprogramowania AI, aby zrozumieć tekst i jego kontekst. Ucząc model, aby rozumiał i analizował duże stosy danych, LLM umożliwia modelom AI zrozumienie, podsumowanie, a nawet klasyfikowanie tekstu w różnych formach i wzorach.
Odpowiadanie na pytania
Duże modele językowe umożliwiają systemom kontroli jakości dokładne wykrywanie zapytań użytkownika w języku naturalnym i odpowiadanie na nie. Jedną z najpopularniejszych aplikacji tego przypadku użycia jest ChatGPT i BERT, które analizują kontekst zapytania i przeszukują duży korpus tekstów w celu znalezienia odpowiednich odpowiedzi na zapytania użytkowników.
[Przeczytaj także: Przyszłość przetwarzania języka: modele i przykłady dużych języków ]

3 podstawowe warunki, aby LLM odniosły sukces
Następujące trzy warunki muszą być dokładnie spełnione, aby zwiększyć wydajność i sprawić, by Twoje duże modele językowe odniosły sukces:
Obecność ogromnych ilości danych do szkolenia modeli
LLM potrzebuje dużych ilości danych do trenowania modeli, które zapewniają wydajne i optymalne wyniki. Istnieją określone metody, takie jak uczenie się transferu i samonadzorowane szkolenie wstępne, które LLM wykorzystują w celu poprawy ich wydajności i dokładności.
Budowanie warstw neuronów w celu ułatwienia tworzenia złożonych wzorców w modelach
Duży model językowy musi zawierać różne warstwy neuronów specjalnie przeszkolonych do rozumienia skomplikowanych wzorców w danych. Neurony w głębszych warstwach mogą lepiej rozumieć złożone wzorce niż warstwy płytsze. Model może nauczyć się powiązań między słowami, pojawiających się razem tematów oraz relacji między częściami mowy.
Optymalizacja LLM do zadań specyficznych dla użytkownika
LLM można dostosować do określonych zadań, zmieniając liczbę warstw, neuronów i funkcji aktywacji. Na przykład model, który przewiduje kolejne słowo w zdaniu, zwykle wykorzystuje mniej warstw i neuronów niż model przeznaczony do generowania nowych zdań od podstaw.
Popularne przykłady dużych modeli językowych
Oto kilka wybitnych przykładów LLM szeroko stosowanych w różnych branżach:
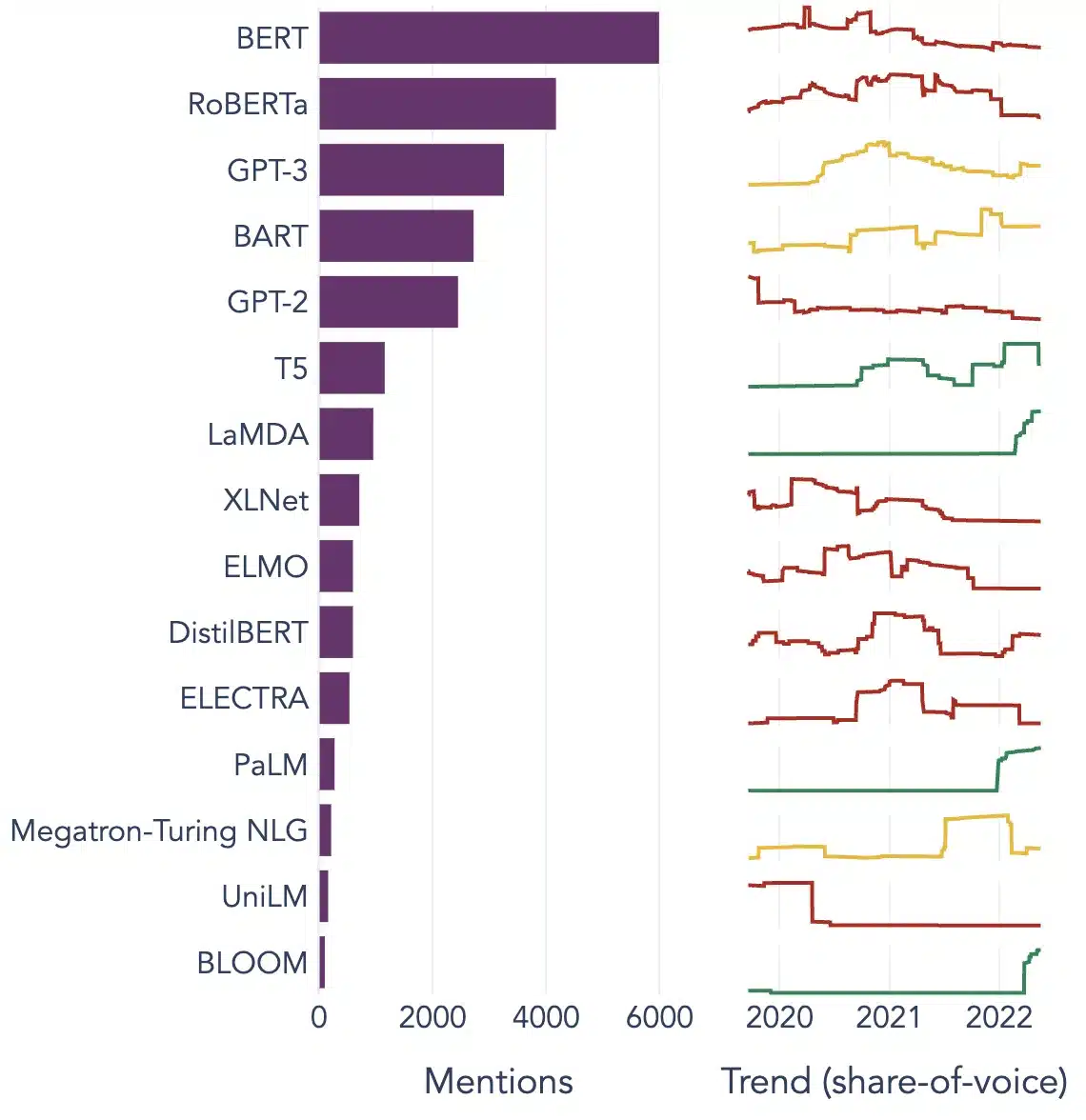
Źródło pliku: W stronę nauki o danych
Wnioski
LLM dostrzegają potencjał zrewolucjonizowania NLP poprzez zapewnienie solidnych i dokładnych możliwości rozumienia języka oraz rozwiązań, które zapewniają bezproblemową obsługę. Aby jednak LLM były bardziej wydajne, programiści muszą wykorzystywać wysokiej jakości dane mowy, aby generować dokładniejsze wyniki i tworzyć wysoce efektywne modele AI.
Shaip to jedno z wiodących rozwiązań w zakresie technologii sztucznej inteligencji, które oferuje szeroki zakres danych mowy w ponad 50 językach i wielu formatach. Dowiedz się więcej o LLM i uzyskaj wskazówki dotyczące swoich projektów od Eksperci Shaip dzisiaj.


