
Dane to supermocarstwo, które zmienia krajobraz cyfrowy w dzisiejszym świecie. Od e-maili po posty w mediach społecznościowych, dane są wszędzie. To prawda, że firmy nigdy nie miały dostępu do tak dużej ilości danych, ale czy sam dostęp do danych jest wystarczający? Bogate źródło informacji staje się bezużyteczne lub przestarzałe, gdy nie jest przetwarzane.
Nieustrukturyzowany tekst może być bogatym źródłem informacji, ale nie będzie przydatny dla firm, jeśli dane nie zostaną uporządkowane, podzielone na kategorie i przeanalizowane. Nieustrukturyzowane dane, takie jak tekst, audio, wideo i media społecznościowe, wynoszą ok 80 -90% wszystkich danych. Co więcej, podobno zaledwie 18% organizacji korzysta z nieustrukturyzowanych danych swojej organizacji.
Ręczne przeszukiwanie terabajtów danych przechowywanych na serwerach jest zadaniem czasochłonnym i szczerze mówiąc niemożliwym. Jednak dzięki postępom w uczeniu maszynowym, przetwarzaniu języka naturalnego i automatyzacji możliwe jest szybkie i efektywne strukturyzowanie i analizowanie danych tekstowych. Pierwszym krokiem w analizie danych jest klasyfikacja tekstu.
Co to jest klasyfikacja tekstu?
Klasyfikacja lub kategoryzacja tekstu to proces grupowania tekstu w z góry określone kategorie lub klasy. Korzystając z tego podejścia do uczenia maszynowego, każdy tekst – dokumenty, pliki internetowe, opracowania, dokumenty prawne, raporty medyczne i inne – można je klasyfikować, organizować i ustrukturyzować.
Klasyfikacja tekstu to podstawowy krok w przetwarzaniu języka naturalnego, który ma kilka zastosowań w wykrywaniu spamu. Analiza nastrojów, wykrywanie intencji, etykietowanie danych i nie tylko.
Możliwe przypadki użycia klasyfikacji tekstu
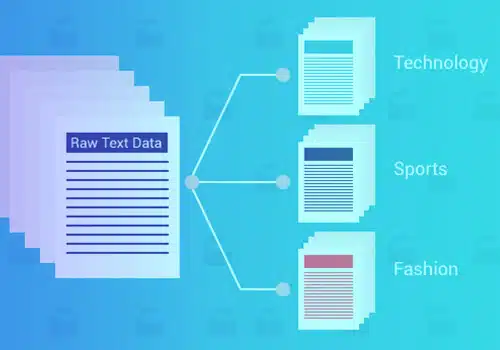 Korzystanie z klasyfikacji tekstu uczenia maszynowego ma kilka zalet, takich jak skalowalność, szybkość analizy, spójność i możliwość podejmowania szybkich decyzji na podstawie konwersacji w czasie rzeczywistym.
Korzystanie z klasyfikacji tekstu uczenia maszynowego ma kilka zalet, takich jak skalowalność, szybkość analizy, spójność i możliwość podejmowania szybkich decyzji na podstawie konwersacji w czasie rzeczywistym.
Kiedy model ML jest szkolony na sztucznej inteligencji, która automatycznie kategoryzuje elementy według wcześniej ustalonych kategorii, możesz szybko zamienić zwykłych przeglądarek w klientów.
Proces klasyfikacji tekstu
Proces klasyfikacji tekstu rozpoczyna się od wstępnego przetwarzania, wyboru funkcji, ekstrakcji i klasyfikacji danych.

Przetwarzanie wstępne
Tokenizacja: Tekst jest podzielony na mniejsze i prostsze formy tekstowe w celu łatwej klasyfikacji.
Normalizacja: Cały tekst w dokumencie musi być na tym samym poziomie zrozumienia. Niektóre formy normalizacji obejmują,
- Zachowanie standardów gramatycznych lub strukturalnych w całym tekście, np. usunięcie spacji lub znaków interpunkcyjnych. Lub zachowanie małych liter w całym tekście.
- Usuwanie przedrostków i sufiksów ze słów i przywracanie ich do ich rdzenia.
- Usuwanie słów stop, takich jak „i” „jest” „the” i innych, które nie dodają wartości do tekstu.
Wybór funkcji
Wybór cech jest podstawowym krokiem w klasyfikacji tekstu. Proces ten ma na celu reprezentowanie tekstów z najbardziej odpowiednią cechą. Wybór funkcji pomaga usunąć nieistotne dane i zwiększyć dokładność.
Wybór cech ogranicza zmienną wejściową do modelu, wykorzystując tylko najbardziej odpowiednie dane i eliminując szum. W zależności od rodzaju szukanego rozwiązania modele sztucznej inteligencji można zaprojektować tak, aby wybierały tylko odpowiednie funkcje z tekstu.
Ekstrakcja cech
Ekstrakcja cech to opcjonalny krok, który niektóre firmy podejmują w celu wyodrębnienia dodatkowych kluczowych cech z danych. Ekstrakcja cech wykorzystuje kilka technik, takich jak mapowanie, filtrowanie i grupowanie. Podstawową korzyścią płynącą z ekstrakcji cech jest to, że pomaga usunąć nadmiarowe dane i poprawić szybkość tworzenia modelu ML.
Tagowanie danych do z góry określonych kategorii
Tagowanie tekstu do predefiniowanych kategorii to ostatni krok w klasyfikacji tekstu. Można to zrobić na trzy różne sposoby,
- Ręczne tagowanie
- Dopasowywanie oparte na regułach
- Algorytmy uczenia się — algorytmy uczenia się można dalej podzielić na dwie kategorie, takie jak tagowanie nadzorowane i tagowanie nienadzorowane.
- Uczenie nadzorowane: Model ML może automatycznie dopasowywać tagi do istniejących skategoryzowanych danych w tagowaniu nadzorowanym. Gdy skategoryzowane dane są już dostępne, algorytmy ML mogą mapować funkcję między tagami a tekstem.
- Uczenie bez nadzoru: Dzieje się tak, gdy brakuje wcześniej istniejących oznakowanych danych. Modele ML wykorzystują klastrowanie i algorytmy oparte na regułach do grupowania podobnych tekstów, na przykład na podstawie historii zakupów produktów, recenzji, danych osobowych i zgłoszeń. Te szerokie grupy można dalej analizować w celu uzyskania cennych spostrzeżeń dotyczących konkretnego klienta, które można wykorzystać do zaprojektowania dostosowanego podejścia do klienta.
Istnieje wiele przypadków użycia klasyfikacji tekstu w różnych branżach. Chociaż gromadzenie, grupowanie, klasyfikowanie i wydobywanie cennych spostrzeżeń z danych tekstowych zawsze było wykorzystywane w kilku dziedzinach, klasyfikacja tekstu znajduje swój potencjał w marketingu, rozwoju produktu, obsłudze klienta, zarządzaniu i administracji. Pomaga firmom zdobywać informacje o konkurencji, rynku i klientach oraz podejmować decyzje biznesowe w oparciu o dane.
Opracowanie skutecznego i wnikliwego narzędzia do klasyfikacji tekstów nie jest łatwe. Mimo to, mając Shaipa jako partnera w zakresie danych, możesz opracować skuteczne, skalowalne i ekonomiczne narzędzie do klasyfikacji tekstu oparte na sztucznej inteligencji. Mamy tony dokładnie opatrzone adnotacjami i gotowe do użycia zbiory danych które można dostosować do unikalnych wymagań Twojego modelu. Zamieniamy Twój tekst w przewagę konkurencyjną; skontaktuj się już dziś.


