
Internet otworzył ludziom drzwi do swobodnego wyrażania opinii, poglądów i sugestii na temat niemal wszystkiego na świecie Media społecznościowe, stron internetowych i blogów. Oprócz wyrażania swoich opinii, ludzie (klienci) mają również wpływ na decyzje zakupowe innych osób. Sentyment, zarówno negatywny, jak i pozytywny, ma kluczowe znaczenie dla każdej firmy lub marki zainteresowanej sprzedażą swoich produktów lub usług.
Pomaganie firmom w wydobywaniu komentarzy do użytku biznesowego jest Przetwarzanie języka naturalnego. Jedna na cztery firmy ma plany wdrożenia technologii NLP w ciągu najbliższego roku, aby wspomagać swoje decyzje biznesowe. Wykorzystując analizę nastrojów, NLP pomaga firmom uzyskiwać interpretowalne spostrzeżenia z surowych i nieustrukturyzowanych danych.
Eksploracja opinii lub Analiza nastrojów jest techniką NLP używaną do dokładnego określenia nastrojów – pozytywne, negatywne lub neutralne – związane z komentarzami i opiniami. Za pomocą NLP słowa kluczowe w komentarzach są analizowane w celu określenia pozytywnych lub negatywnych słów zawartych w słowie kluczowym.
Nastroje są oceniane w systemie skalowania, który przypisuje oceny nastrojów do emocji w fragmencie tekstu (określając tekst jako pozytywny lub negatywny).
Co to jest wielojęzyczna analiza nastrojów?

Jak sama nazwa wskazuje, wielojęzyczna analiza nastrojów to technika przeprowadzania ocen tonacji dla więcej niż jednego języka. Jednak nie jest to takie proste. Nasza kultura, język i doświadczenia mają ogromny wpływ na nasze zachowania zakupowe i emocje. Bez dobrego zrozumienia języka, kontekstu i kultury użytkownika niemożliwe jest dokładne zrozumienie jego intencji, emocji i interpretacji.
Podczas gdy automatyzacja jest odpowiedzią na wiele naszych współczesnych problemów, tłumaczenie maszynowe oprogramowanie nie będzie w stanie wychwycić niuansów języka, kolokwializmów, subtelności i odniesień kulturowych w komentarzach i recenzje produktu to się tłumaczy. Narzędzie ML może zapewnić tłumaczenie, ale może nie być przydatne. To jest powód, dla którego wymagana jest wielojęzyczna analiza tonacji.
Dlaczego potrzebna jest wielojęzyczna analiza nastrojów?
Większość firm używa języka angielskiego jako środka komunikacji, ale większość konsumentów na całym świecie nie używa go.
Według Ethnologue około 13% światowej populacji mówi po angielsku. Dodatkowo British Council stwierdza, że około 25% światowej populacji ma przyzwoitą znajomość języka angielskiego. Jeśli wierzyć tym liczbom, to duża część konsumentów komunikuje się ze sobą iz firmą w języku innym niż angielski.
Jeśli głównym celem przedsiębiorstw jest utrzymanie bazy klientów w stanie nienaruszonym i przyciąganie nowych klientów, muszą one dogłębnie zrozumieć opinie ich klientów wyrażone w ich język ojczysty. Ręczne przeglądanie każdego komentarza lub tłumaczenie go na język angielski jest uciążliwym procesem, który nie przyniesie skutecznych rezultatów.
Trwałym rozwiązaniem jest rozwój wielojęzyczności systemy analizy nastrojów które wykrywają i analizują opinie, emocje i sugestie klientów w mediach społecznościowych, forach, ankietach i nie tylko.
Etapy przeprowadzania wielojęzycznej analizy nastrojów
Analiza nastrojów, niezależnie od tego, czy w jednym języku, czy wiele języków, to proces, który wymaga zastosowania modeli uczenia maszynowego, przetwarzania języka naturalnego i technik analizy danych w celu wyodrębnienia wielojęzyczna ocena nastrojów z danych.
Kroki związane z wielojęzyczną analizą nastrojów to
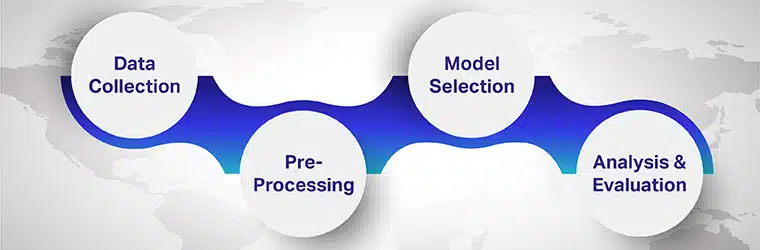
Krok 1: Zbieranie danych
Zbieranie danych to pierwszy krok w stosowaniu analizy nastrojów. Aby utworzyć wielojęzyczny model analizy nastrojów, ważne jest, aby pozyskiwać dane w różnych językach. Wszystko będzie zależeć od jakości zebranych, opatrzonych adnotacjami i oznaczonych danych. Możesz pobierać dane z interfejsów API, repozytoriów open source i wydawców.
Krok 2: Wstępne przetwarzanie
Zebrane dane sieciowe powinny zostać oczyszczone, a informacje z nich zebrane. Części tekstu, które nie przekazują żadnego szczególnego znaczenia, takie jak „jest” i inne, powinny zostać usunięte. Ponadto tekst należy pogrupować w grupy słów, które zostaną podzielone na kategorie w celu przekazania pozytywnego lub negatywnego znaczenia.
Aby poprawić jakość klasyfikacji, treść powinna zostać oczyszczona z szumów, takich jak znaczniki HTML, reklamy i skrypty. Język, leksykon i gramatyka używane przez ludzi różnią się w zależności od sieci społecznościowej. Ważne jest, aby takie treści znormalizować i przygotować do wstępnej obróbki.
Kolejnym krytycznym krokiem w przetwarzaniu wstępnym jest wykorzystanie przetwarzania języka naturalnego do dzielenia zdań, usuwania słów kończących, oznaczania części mowy, przekształcania słów w ich formę podstawową oraz tokenizacji słów w symbole i tekst.
Krok 3: Wybór modelu
Model oparty na regułach: Najprostsza metoda wielojęzycznej analizy semantycznej jest oparta na regułach. Algorytm oparty na regułach przeprowadza analizę w oparciu o zestaw z góry określonych reguł zaprogramowanych przez ekspertów.
Reguła może określać słowa lub wyrażenia, które są pozytywne lub negatywne. Na przykład recenzja produktu lub usługi może zawierać pozytywne lub negatywne słowa, takie jak „świetne”, „wolne”, „poczekaj” i „przydatne”. Ta metoda ułatwia klasyfikowanie słów, ale może błędnie klasyfikować słowa skomplikowane lub rzadziej występujące.
Model automatyczny: Model automatyczny przeprowadza wielojęzyczną analizę sentymentu bez udziału ludzkich moderatorów. Chociaż model uczenia maszynowego jest tworzony przy użyciu ludzkiego wysiłku, może działać automatycznie, aby dostarczać dokładne wyniki po opracowaniu.
Dane testowe są analizowane, a każdy komentarz jest ręcznie oznaczany jako pozytywny lub negatywny. Model ML nauczy się następnie z danych testowych, porównując nowy tekst z istniejącymi komentarzami i kategoryzując je.
Krok 4: Analiza i ocena
Modele oparte na regułach i modele uczenia maszynowego można ulepszać i ulepszać w miarę upływu czasu i zdobywania doświadczenia. Leksykon rzadziej używanych słów lub wyniki na żywo dla wielojęzycznych nastrojów można aktualizować w celu szybszej i dokładniejszej klasyfikacji.
Wyzwanie tłumaczenia
Czy tłumaczenie nie wystarczy? Właściwie nie!
Tłumaczenie polega na przeniesieniu tekstu lub grup tekstów z jednego języka i znalezieniu odpowiednika w innym. Jednak tłumaczenie nie jest ani proste, ani skuteczne.
To dlatego, że ludzie używają języka nie tylko do komunikowania swoich potrzeb, ale także do wyrażania swoich emocji. Ponadto istnieją wyraźne różnice między różnymi językami, takimi jak angielski, hindi, mandaryński i tajski. Dodaj do tej literackiej mieszanki emocje, slang, idiomy, sarkazm i emotikony. Nie jest możliwe uzyskanie dokładnego tłumaczenia tekstu.
Niektóre z głównych wyzwań tłumaczenie maszynowe jest
- Subiektywność
- Kontekst
- Slang i idiomy
- Sarkazm
- Porównania
- Neutralność
- Emoji i współczesne użycie słów.
Bez dokładnego zrozumienia zamierzonego znaczenia recenzji, komentarzy i komunikatów dotyczących ich produktów, cen, usług, funkcji i jakości, firmy nie będą w stanie zrozumieć potrzeb i opinii klientów.
Wielojęzyczna analiza nastrojów to trudny proces. Każdy język ma swój unikalny leksykon, składnię, morfologię i fonologię. Dodaj do tego kulturę, slang, wyrażone uczucia, sarkazm i ton, a otrzymasz wymagającą łamigłówkę, która wymaga wydajnego rozwiązania uczenia maszynowego opartego na sztucznej inteligencji.
Do opracowania solidnej wielojęzyczności potrzebny jest kompleksowy wielojęzyczny zestaw danych narzędzia do analizy sentymentu które mogą przetwarzać recenzje i dostarczać firmom zaawansowanych informacji. Shaip jest liderem na rynku w dostarczaniu dostosowanych do branży, oznakowanych i opatrzonych adnotacjami zestawów danych w kilku językach, które pomagają w opracowywaniu wydajnych i dokładnych wielojęzyczne rozwiązania do analizy nastrojów.


