Jeśli używasz Siri, Alexy, Cortany, Amazon Echo lub innych w swoim codziennym życiu, zaakceptujesz to Rozpoznawanie mowy stał się wszechobecną częścią naszego życia. Te oparte na sztucznej inteligencji asystenci głosowi przekształcają werbalne zapytania użytkowników na tekst, interpretują i rozumieją, co mówi użytkownik, aby uzyskać odpowiednią odpowiedź.
Istnieje potrzeba gromadzenia wysokiej jakości danych w celu opracowania niezawodnych modeli mowy i rozpoznawania. Ale rozwijając się oprogramowanie do rozpoznawania mowy nie jest zadaniem prostym – właśnie dlatego, że transkrypcja mowy ludzkiej w całej jej złożoności, takiej jak rytm, akcent, wysokość i wyrazistość, jest trudna. A kiedy dodasz emocje do tej złożonej mieszanki, staje się to wyzwaniem.
Co to jest rozpoznawanie mowy?
Rozpoznawanie mowy to zdolność oprogramowania do rozpoznawania i przetwarzania ludzka mowa na tekst. Chociaż różnica między rozpoznawaniem głosu a rozpoznawaniem mowy może wydawać się dla wielu subiektywna, istnieją między nimi pewne fundamentalne różnice.
Chociaż zarówno mowa, jak i rozpoznawanie głosu stanowią część technologii asystenta głosowego, pełnią one dwie różne funkcje. Rozpoznawanie mowy dokonuje automatycznej transkrypcji ludzkiej mowy i poleceń na tekst, podczas gdy rozpoznawanie głosu zajmuje się tylko rozpoznawaniem głosu mówiącego.
Rodzaje rozpoznawania mowy
Zanim wskoczymy do typy rozpoznawania mowy, przyjrzyjmy się pokrótce danym rozpoznawania mowy.
Dane rozpoznawania mowy to zbiór nagrań dźwiękowych mowy ludzkiej i transkrypcji tekstu, które pomagają trenować systemy uczenia maszynowego do rozpoznawania głosu.
Nagrania audio i transkrypcje są wprowadzane do systemu ML, aby algorytm mógł zostać wyszkolony w rozpoznawaniu niuansów mowy i rozumieniu jej znaczenia.
Chociaż istnieje wiele miejsc, w których można uzyskać bezpłatne, gotowe zestawy danych, najlepiej jest to zrobić dostosowane zbiory danych dla Twoich projektów. Możesz wybrać rozmiar kolekcji, wymagania dotyczące dźwięku i głośników oraz język, korzystając z niestandardowego zestawu danych.
Spektrum danych mowy
Dane mowy Spectrum identyfikuje jakość i ton mowy w zakresie od naturalnej do nienaturalnej.
Skryptowe dane rozpoznawania mowy
Jak sama nazwa wskazuje, mowa skryptowa to kontrolowana forma danych. Prelegenci zapisują określone frazy z przygotowanego tekstu. Są one zwykle używane do dostarczania poleceń, podkreślając, w jaki sposób słowo lub fraza mówi się, a nie to, co się mówi.
Rozpoznawanie mowy oparte na skryptach można wykorzystać podczas opracowywania asystenta głosowego, który powinien odbierać polecenia wydawane przy użyciu różnych akcentów mówcy.
Rozpoznawanie mowy na podstawie scenariuszy
W przemówieniu opartym na scenariuszach mówca jest proszony o wyobrażenie sobie konkretnego scenariusza i wydanie polecenia głosowe na podstawie scenariusza. W ten sposób wynikiem jest zbiór poleceń głosowych, które nie są oskryptowane, ale kontrolowane.
Programiści, którzy chcą opracować urządzenie, które rozumie codzienną mowę z jej różnymi niuansami, wymagają danych mowy opartych na scenariuszach. Na przykład pytanie o drogę do najbliższej Pizza Hut za pomocą różnych pytań.
Naturalne rozpoznawanie mowy
Na samym końcu spektrum mowy znajduje się mowa spontaniczna, naturalna i niekontrolowana w żaden sposób. Mówca mówi swobodnie, używając swojego naturalnego tonu rozmowy, języka, wysokości tonu i tenoru.
Jeśli chcesz nauczyć aplikację opartą na ML w zakresie rozpoznawania mowy z wieloma głośnikami, to mowa konwersacyjna zestaw danych jest przydatny.
Komponenty gromadzenia danych dla projektów mowy
 Szereg kroków związanych z gromadzeniem danych mowy zapewnia jakość zebranych danych i pomaga w trenowaniu wysokiej jakości modeli opartych na sztucznej inteligencji.
Szereg kroków związanych z gromadzeniem danych mowy zapewnia jakość zebranych danych i pomaga w trenowaniu wysokiej jakości modeli opartych na sztucznej inteligencji.
Zrozum wymagane odpowiedzi użytkownika
Zacznij od zrozumienia wymaganych odpowiedzi użytkownika dla modelu. Aby opracować model rozpoznawania mowy, należy zebrać dane, które ściśle reprezentują potrzebną treść. Zbieraj dane z rzeczywistych interakcji, aby zrozumieć interakcje i odpowiedzi użytkowników. Jeśli tworzysz asystenta czatu opartego na sztucznej inteligencji, spójrz na dzienniki czatu, nagrania rozmów, odpowiedzi w oknie dialogowym czatu, aby utworzyć zestaw danych.
Przyjrzyj się językowi specyficznemu dla domeny
Do zestawu danych rozpoznawania mowy wymagana jest zawartość ogólna i specyficzna dla domeny. Po zebraniu ogólnych danych mowy należy je przesiać i oddzielić ogólne od szczegółowych.
Na przykład klienci mogą zadzwonić, aby poprosić o wizytę w celu sprawdzenia jaskry w ośrodku okulistycznym. Prośba o wizytę jest terminem bardzo ogólnym, ale jaskra jest specyficzna dla domeny.
Co więcej, podczas trenowania modelu rozpoznawania mowy ML, upewnij się, że trenujesz go tak, aby identyfikował frazy, a nie indywidualnie rozpoznane słowa.
Nagraj ludzką mowę
Po zebraniu danych z poprzednich dwóch kroków, następny krok obejmowałby nakłonienie ludzi do zarejestrowania zebranych stwierdzeń.
Niezbędne jest zachowanie idealnej długości skryptu. Proszenie ludzi o przeczytanie więcej niż 15 minut tekstu może przynieść efekt przeciwny do zamierzonego. Zachowaj co najmniej 2-3 sekundy przerwy między każdym nagranym stwierdzeniem.
Pozwól, aby nagranie było dynamiczne
Zbuduj repozytorium mowy różnych osób, mówiących akcentów, stylów zapisanych w różnych okolicznościach, urządzeniach i środowiskach. Jeśli większość przyszłych użytkowników będzie korzystać z telefonu stacjonarnego, baza danych kolekcji mowy powinna mieć znaczącą reprezentację spełniającą to wymaganie.

Wywołaj zmienność w nagrywaniu mowy
Po skonfigurowaniu środowiska docelowego poproś osoby zbierające dane o przeczytanie przygotowanego skryptu w podobnym środowisku. Poproś uczestników, aby nie martwili się błędami i zachowali jak najbardziej naturalny przekaz. Pomysł polega na tym, aby duża grupa ludzi nagrywała scenariusz w tym samym środowisku.
Transkrybuj przemówienia
Po nagraniu skryptu z wykorzystaniem wielu tematów (z błędami) należy przystąpić do transkrypcji. Zachowaj błędy nienaruszone, ponieważ pomogłoby to osiągnąć dynamikę i różnorodność gromadzonych danych.
Zamiast zmuszać ludzi do transkrypcji całego tekstu słowo po słowie, możesz skorzystać z mechanizmu zamiany mowy na tekst do wykonania transkrypcji. Sugerujemy jednak również, abyś zatrudnił transkrybujących ludzi, aby poprawić błędy.
Opracuj zestaw testowy
Opracowanie zestawu testowego ma kluczowe znaczenie, ponieważ jest liderem w model języka.
Zrób parę mowy i odpowiedniego tekstu i podziel je na segmenty.
Po zebraniu zebranych elementów wyodrębnij próbkę 20%, która tworzy zestaw testowy. Nie jest to zestaw szkoleniowy, ale te wyodrębnione dane poinformują Cię, czy wyszkolony model dokonuje transkrypcji dźwięku, na którym nie został przeszkolony.
Zbuduj model szkolenia językowego i miarę
Teraz zbuduj model języka rozpoznawania mowy, używając instrukcji specyficznych dla domeny i dodatkowych odmian, jeśli zajdzie taka potrzeba. Po wytrenowaniu modelu należy zacząć go mierzyć.
Weź model uczący (z 80% wybranych segmentów audio) i przetestuj go względem zestawu testowego (wyodrębniony 20% zestaw danych), aby sprawdzić przewidywania i wiarygodność. Sprawdź błędy, wzorce i skup się na czynnikach środowiskowych, które można naprawić.
Możliwe przypadki użycia lub aplikacje
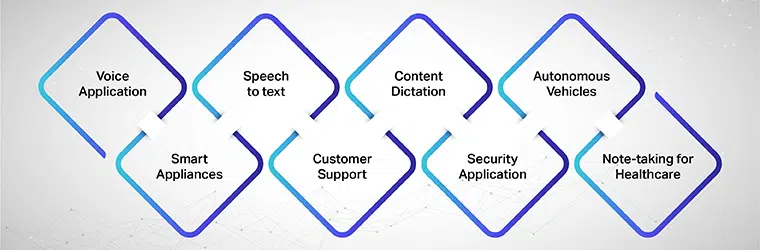
Aplikacja głosowa, urządzenia inteligentne, zamiana mowy na tekst, obsługa klienta, dyktowanie treści, aplikacja zabezpieczająca, pojazdy autonomiczne, sporządzanie notatek w służbie zdrowia.
Rozpoznawanie mowy otwiera świat możliwości, a wykorzystanie aplikacji głosowych przez użytkowników wzrosło na przestrzeni lat.
Niektóre z typowych zastosowań technologia rozpoznawania mowy zawierać:
Aplikacja wyszukiwania głosowego
Według Google około 20% wyszukiwań przeprowadzanych w aplikacji Google to głos. Osiem miliardów ludzi przewiduje się, że będą korzystać z asystentów głosowych do 2023 r., co stanowi gwałtowny wzrost w porównaniu z przewidywanymi 6.4 mld w 2022 r.
Popularność wyszukiwania głosowego znacznie wzrosła na przestrzeni lat i przewiduje się, że trend ten będzie się utrzymywał. Konsumenci polegają na wyszukiwaniu głosowym przy wyszukiwaniu zapytań, kupowaniu produktów, lokalizowaniu firm, znajdowaniu lokalnych firm i nie tylko.
Urządzenia domowe/inteligentne urządzenia
Technologia rozpoznawania głosu jest wykorzystywana do wydawania poleceń głosowych inteligentnym urządzeniom domowym, takim jak telewizory, światła i inne urządzenia. 66% konsumentów w Wielkiej Brytanii, Stanach Zjednoczonych i Niemczech stwierdzili, że korzystają z asystentów głosowych podczas korzystania z inteligentnych urządzeń i głośników.
Mowa do tekstu
Aplikacje zamiany mowy na tekst są używane do pomocy w swobodnym przetwarzaniu podczas pisania wiadomości e-mail, dokumentów, raportów i innych. Mowa do tekstu eliminuje czas potrzebny na przepisywanie dokumentów, pisanie książek i wiadomości e-mail, tworzenie napisów do filmów i tłumaczenie tekstu.
Obsługa klienta
Aplikacje do rozpoznawania mowy są wykorzystywane głównie w obsłudze klienta i wsparciu. System rozpoznawania mowy pomaga w dostarczaniu rozwiązań obsługi klienta 24/7 po przystępnej cenie przy ograniczonej liczbie przedstawicieli.
Dyktowanie treści
Dyktowanie treści to kolejny przypadek użycia rozpoznawania mowy który pomaga studentom i naukowcom pisać obszerne treści w ułamku czasu. Jest to bardzo pomocne dla uczniów znajdujących się w niekorzystnej sytuacji z powodu ślepoty lub problemów ze wzrokiem.
Aplikacja bezpieczeństwa
Rozpoznawanie głosu jest szeroko wykorzystywane do celów bezpieczeństwa i uwierzytelniania poprzez identyfikowanie unikalnych cech głosu. Zamiast zmuszać osobę do identyfikacji przy użyciu skradzionych lub niewłaściwie wykorzystanych danych osobowych, biometria głosowa zwiększa bezpieczeństwo.
Co więcej, rozpoznawanie głosu do celów bezpieczeństwa poprawiło poziom zadowolenia klientów, ponieważ eliminuje rozszerzony proces logowania i duplikację poświadczeń.
Polecenia głosowe dla pojazdów
Pojazdy, głównie samochody, mają teraz wspólną funkcję rozpoznawania głosu, która zwiększa bezpieczeństwo jazdy. Pomaga kierowcom skupić się na prowadzeniu pojazdu, akceptując proste polecenia głosowe, takie jak wybieranie stacji radiowych, wykonywanie połączeń lub zmniejszanie głośności.
Robienie notatek dla służby zdrowia
Oprogramowanie do transkrypcji medycznej zbudowane przy użyciu algorytmów rozpoznawania mowy z łatwością przechwytuje notatki głosowe lekarzy, polecenia, diagnozy i objawy. Sporządzanie notatek medycznych zwiększa jakość i pilność w branży opieki zdrowotnej.
Czy masz na myśli projekt rozpoznawania mowy, który może zmienić Twój biznes? Wszystko, czego możesz potrzebować, to dostosowany zestaw danych rozpoznawania mowy.
Oprogramowanie do rozpoznawania mowy oparte na sztucznej inteligencji musi być przeszkolone na wiarygodnych zestawach danych dotyczących algorytmów uczenia maszynowego, aby zintegrować składnię, gramatykę, strukturę zdań, emocje i niuanse ludzkiej mowy. Co najważniejsze, oprogramowanie powinno stale się uczyć i reagować – rosnąć z każdą interakcją.
W Shaip zapewniamy całkowicie dostosowane zestawy danych do rozpoznawania mowy na potrzeby różnych projektów uczenia maszynowego. Dzięki Shaip masz dostęp do najwyższej jakości dane treningowe szyte na miarę które można wykorzystać do zbudowania i wprowadzenia na rynek niezawodnego systemu rozpoznawania mowy. Skontaktuj się z naszymi ekspertami, aby uzyskać pełne zrozumienie naszej oferty.
[Przeczytaj także: Kompletny przewodnik po konwersacyjnej sztucznej inteligencji]