
Systemy automatycznego rozpoznawania mowy i wirtualni asystenci, tacy jak Siri, Alexa i Cortana, stały się powszechnymi elementami naszego życia. Nasza zależność od nich znacznie wzrasta, gdy stają się mądrzejsze. Od włączania światła, przez dzwonienie po zmianę kanałów telewizyjnych, wykorzystujemy te inteligentne technologie do wykonywania przyziemnych zadań.
Jednak czy kiedykolwiek zastanawiałeś się, jak działają te systemy rozpoznawania mowy?
Cóż, ten blog nauczy Cię podstaw automatycznego rozpoznawania mowy. Zbadamy również jego działanie i sposób budowy funkcjonalnych wirtualnych asystentów, takich jak Siri.
Co to jest automatyczne rozpoznawanie mowy?
Automatyczne rozpoznawanie mowy (ASR) to oprogramowanie, które umożliwia systemowi komputerowemu konwersję ludzkiej mowy na tekst, wykorzystując wiele algorytmów sztucznej inteligencji i uczenia maszynowego.
Po przekonwertowaniu i przeanalizowaniu danego polecenia, komputer odpowiada odpowiednim wyjściem dla użytkownika. ASR został po raz pierwszy wprowadzony w 1962 roku i od tego czasu stale ulepsza swoje operacje i zyskuje ogromne zainteresowanie dzięki popularnym aplikacjom, takim jak Alexa i Siri.
Na czym polega proces gromadzenia mowy w celu uczenia modeli ASR?
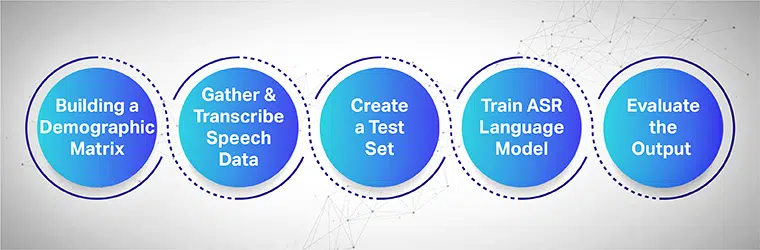
Zbieranie mowy ma na celu zebranie kilku przykładowych nagrań z wielu obszarów wykorzystywanych do zasilania i trenowania modeli ASR. System ASR zapewnia najwyższą wydajność, gdy duże zbiory danych mowy i dźwięku są gromadzone i dostarczane do jego systemu.
Aby działać bezproblemowo, zebrane zestawy danych mowy muszą zawierać wszystkie docelowe dane demograficzne, języki, akcenty i dialekty. Poniższy proces pokazuje, jak trenować model uczenia maszynowego w wielu krokach:
Zacznij od zbudowania macierzy demograficznej
Przede wszystkim zbiera dane dla różnych danych demograficznych, takich jak lokalizacja, płeć, język, wiek i akcent. Upewnij się również, że wychwytujesz różne dźwięki otoczenia, takie jak hałas uliczny, hałas poczekalni, hałas biurowy itp.
Zbierz i transkrybuj dane mowy
Następnym krokiem jest zebranie próbek ludzkiego dźwięku i mowy w różnych lokalizacjach geograficznych w celu wytrenowania modelu ASR. Jest to ważny krok i wymaga od ekspertów-ludzi wypowiadania długich i krótkich wypowiedzi słów, aby uzyskać autentyczne wrażenie zdania i powtarzania tych samych zdań w różnych akcentach i dialektach.
Utwórz oddzielny zestaw testowy
Po zebraniu transkrybowanego tekstu następnym krokiem jest sparowanie go z odpowiednimi danymi audio. Następnie podziel dane dalej i dołącz jedno z nich. Teraz z podzielonych na segmenty par danych możesz pobrać losowe dane ze zbioru do dalszych testów.
Trenuj swój model językowy ASR
Im więcej informacji mają twoje zbiory danych, tym lepsze będzie działanie modelu wytrenowanego przez sztuczną inteligencję. Dlatego generuj wiele wariacji tekstu i przemówień, które nagrałeś wcześniej. Parafrazuj te same zdania, używając różnych notacji mowy.
Oceń dane wyjściowe i na koniec wykonaj iterację
Na koniec mierzy dane wyjściowe modelu ASR, aby naprawić jego wydajność. Przetestuj model względem zestawu testowego, aby określić jego wydajność. Odpowiednio, zaangażuj swój model ASR w pętlę sprzężenia zwrotnego, aby wygenerować pożądane wyniki i naprawić wszelkie luki.
[Przeczytaj także: Kompleksowy przegląd automatycznego rozpoznawania mowy]

Jakie są różne przypadki użycia rozpoznawania mowy?
Technologia rozpoznawania mowy jest obecnie szeroko rozpowszechniona w wielu gałęziach przemysłu. Niektóre branże wykorzystujące tę niesamowitą technologię to:
 Przemysł spożywczy: Giganty żywnościowe, takie jak Wendy's i McDonald's, mają na celu poprawę doświadczeń klientów za pomocą ASR. W wielu swoich placówkach wdrożyli w pełni funkcjonalne modele ASR do przyjmowania zamówień, a następnie przekazują je do sekcji gotowania, aby przygotować zamówienie klienta.
Przemysł spożywczy: Giganty żywnościowe, takie jak Wendy's i McDonald's, mają na celu poprawę doświadczeń klientów za pomocą ASR. W wielu swoich placówkach wdrożyli w pełni funkcjonalne modele ASR do przyjmowania zamówień, a następnie przekazują je do sekcji gotowania, aby przygotować zamówienie klienta.- Telekomunikacja: Vodafone jest jednym z największych dostawców usług telekomunikacyjnych na świecie. Firma zaprojektowała swoje usługi obsługi klienta i przekaźników telefonicznych, wykorzystując modele ASR, które pomagają w rozwiązywaniu różnych zapytań i przekierowywaniu połączeń do zainteresowanych działów.
- Podróże i transport: Google Android Auto czy Apple CarPlay stały się powszechne. Większość ludzi używa ich do aktywacji systemów nawigacji, wysyłania wiadomości lub przełączania list odtwarzania muzyki. Jednak wraz z postępem technologicznym takie systemy stają się coraz bardziej wyrafinowane.
Inteligentny asystent osobisty BMW wprowadzony w BMW serii 3 jest znacznie inteligentniejszy od zwykłych asystentów głosowych. Umożliwia kierowcom wyszukiwanie informacji związanych z samochodem i obsługę samochodu za pomocą poleceń głosowych. - Media i rozrywka: Również branża medialna wykorzystuje ASR w wielu swoich projektach. Youtube uruchomił asystenta opartego na sztucznej inteligencji, który generuje automatyczne napisy na żywo. Gdy będziesz mówić na ekranie, asystent udostępni napisy, aby film był dostępny dla większej grupy użytkowników YouTube.
 Przemysł spożywczy: Giganty żywnościowe, takie jak Wendy's i McDonald's, mają na celu poprawę doświadczeń klientów za pomocą ASR. W wielu swoich placówkach wdrożyli w pełni funkcjonalne modele ASR do przyjmowania zamówień, a następnie przekazują je do sekcji gotowania, aby przygotować zamówienie klienta.
Przemysł spożywczy: Giganty żywnościowe, takie jak Wendy's i McDonald's, mają na celu poprawę doświadczeń klientów za pomocą ASR. W wielu swoich placówkach wdrożyli w pełni funkcjonalne modele ASR do przyjmowania zamówień, a następnie przekazują je do sekcji gotowania, aby przygotować zamówienie klienta. Telekomunikacja: Vodafone jest jednym z największych dostawców usług telekomunikacyjnych na świecie. Firma zaprojektowała swoje usługi obsługi klienta i przekaźników telefonicznych, wykorzystując modele ASR, które pomagają w rozwiązywaniu różnych zapytań i przekierowywaniu połączeń do zainteresowanych działów.
Telekomunikacja: Vodafone jest jednym z największych dostawców usług telekomunikacyjnych na świecie. Firma zaprojektowała swoje usługi obsługi klienta i przekaźników telefonicznych, wykorzystując modele ASR, które pomagają w rozwiązywaniu różnych zapytań i przekierowywaniu połączeń do zainteresowanych działów. Podróże i transport: Google Android Auto czy Apple CarPlay stały się powszechne. Większość ludzi używa ich do aktywacji systemów nawigacji, wysyłania wiadomości lub przełączania list odtwarzania muzyki. Jednak wraz z postępem technologicznym takie systemy stają się coraz bardziej wyrafinowane.
Podróże i transport: Google Android Auto czy Apple CarPlay stały się powszechne. Większość ludzi używa ich do aktywacji systemów nawigacji, wysyłania wiadomości lub przełączania list odtwarzania muzyki. Jednak wraz z postępem technologicznym takie systemy stają się coraz bardziej wyrafinowane. Media i rozrywka: Również branża medialna wykorzystuje ASR w wielu swoich projektach. Youtube uruchomił asystenta opartego na sztucznej inteligencji, który generuje automatyczne napisy na żywo. Gdy będziesz mówić na ekranie, asystent udostępni napisy, aby film był dostępny dla większej grupy użytkowników YouTube.
Media i rozrywka: Również branża medialna wykorzystuje ASR w wielu swoich projektach. Youtube uruchomił asystenta opartego na sztucznej inteligencji, który generuje automatyczne napisy na żywo. Gdy będziesz mówić na ekranie, asystent udostępni napisy, aby film był dostępny dla większej grupy użytkowników YouTube.
[Przeczytaj także: Co to jest technologia zamiany mowy na tekst i jak działa]
Jak Shaip może pomóc?
Shaip to jedna z wiodących usług szkoleniowych w zakresie sztucznej inteligencji, która posiada doświadczenie w wielu obszarach sztucznej inteligencji i ML. Mogą pomóc w zbudowaniu własnego zestawu danych, który można wykorzystać w różnych aplikacjach i projektach.
Niektóre z usług świadczonych przez Shaip to:
- Automatyczne rozpoznawanie mowy (ASR)
- Kolekcja mowy skryptowej
- Transkreacja
- Spontaniczna kolekcja mowy
- Zbieranie wypowiedzi/słowa pobudki,
- Zamiana tekstu na mowę (TTS)
Możesz skorzystać z tych usług, aby uzyskać najlepsze wyniki dla swoich projektów opartych na sztucznej inteligencji. Dowiedz się więcej o tych usługach, kontaktując się z naszym zespołem ekspertów już dziś!


